微服务容器化迁移
从运维角度看微服务
单体应用 vs 微服务
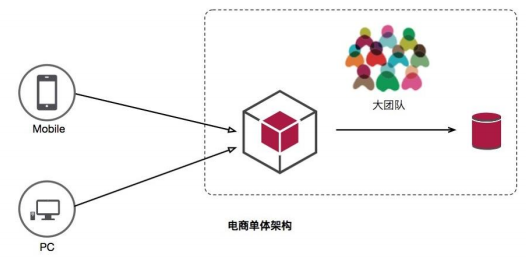
特点:
-
易于部署
-
易于测试
不足:
-
代码膨胀,难以维护
-
构建、部署成本大
-
新人上手难
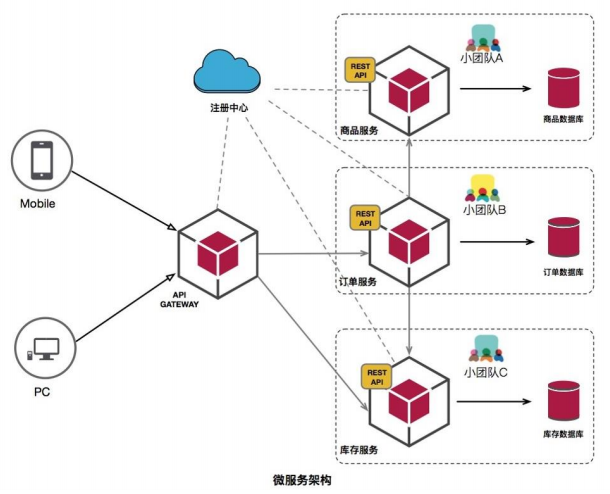
微服务特点
服务组件化
每个服务独立开发、部署,有效避免一个服务的修改引起整个系统重新部署。
技术栈灵活
约定通信方式,使得服务本身功能实现对技术要求不再那么敏感。
独立部署
每个微服务独立部署,加快部署速度,方便扩展。
扩展性强
每个微服务可以部署多个,并且有负载均衡能力。
独立数据
每个微服务有独立的基本组件,例如数据库、缓存等。
微服务不足
-
沟通成本
-
数据一致性
-
运维成本:部署、监控
-
内部架构复杂性
-
大量服务治理
Java微服务框架
-
Spring Boot:快速开发微服务的框架
-
Spring Cloud:基于SpringBoot实现的一个完整的微服务解决方案
-
Dubbo:阿里巴巴开源的微服务治理框架
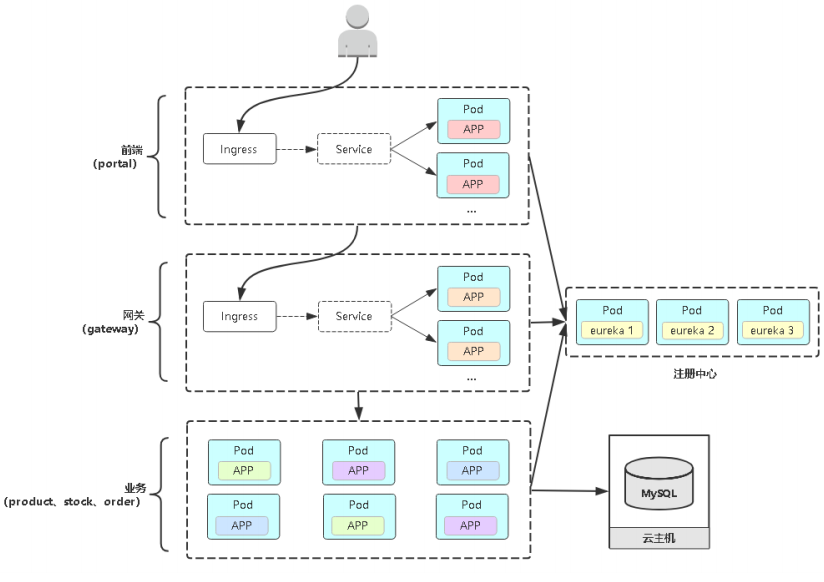
在K8s平台部署微服务考虑的问题
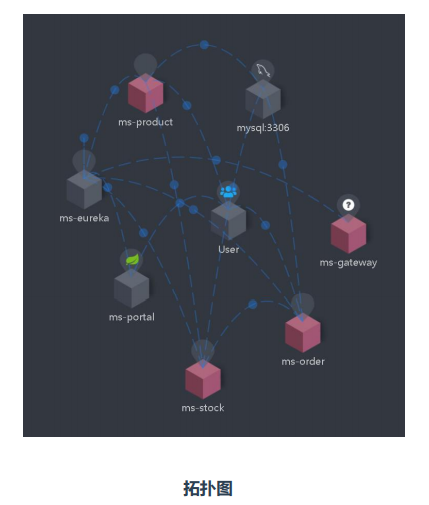
常见微服务架构图
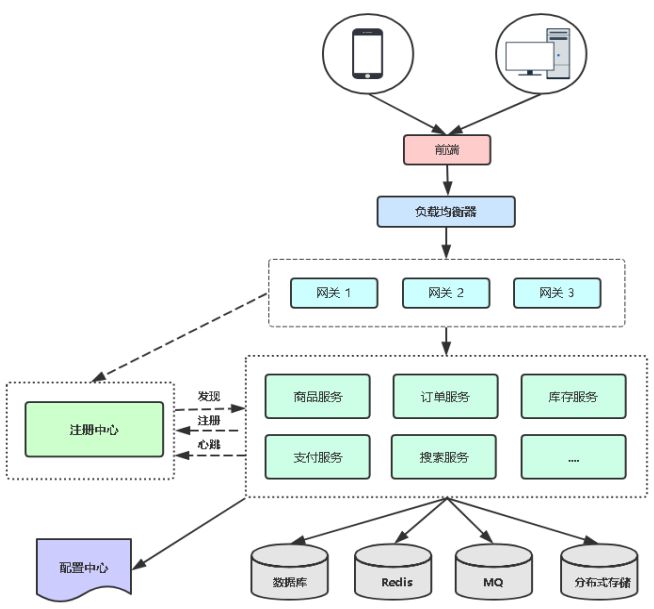
对微服务项目架构理解
-
微服务间如何通信?REST API,RPC,MQ
-
微服务如何发现彼此?注册中心
-
组件之间怎么个调用关系?
-
哪个服务作为整个网站入口?前后端分离
-
哪些微服务需要对外访问?前端和微服务网关
-
微服务怎么部署?更新?扩容?
-
区分有状态应用与无状态应用
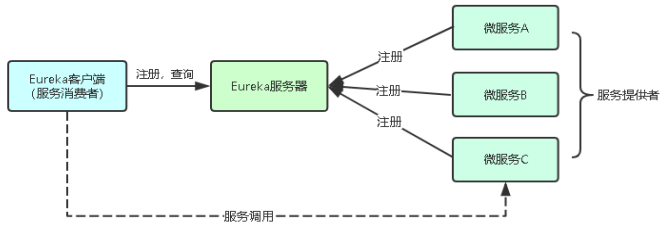
为什么用注册中心系统
微服务太多面临的问题:
-
怎么记录一个微服务多个副本接口地址?
-
怎么实现一个微服务多个副本负载均衡?
-
怎么判断一个微服务副本是否可用?
主流注册中心:Eureka,Nacos,Consul
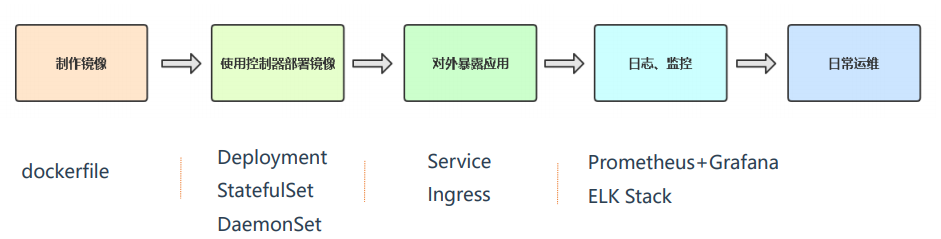
在K8s部署项目流程
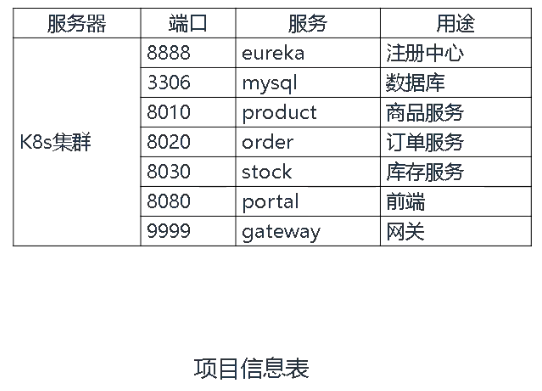
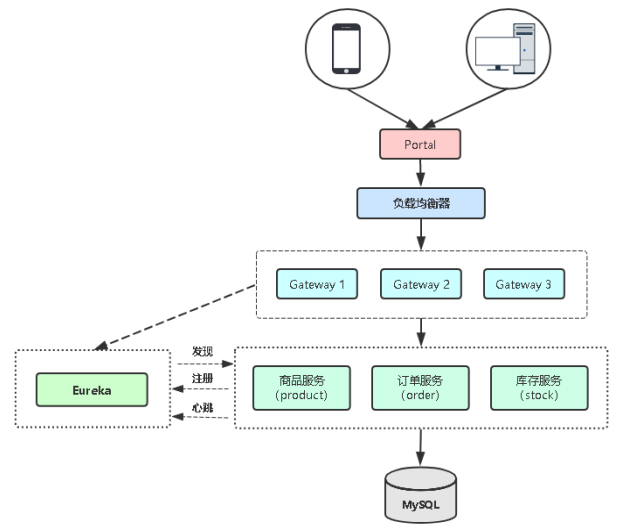
在K8S平台部署Spring Cloud微服务项目
容器化微服务项目实施步骤
具体步骤:
第一步:熟悉Spring Cloud微服务项目
第二步:源代码编译构建
第三步:构建项目镜像并推送到镜像仓库
第四步:K8s服务编排
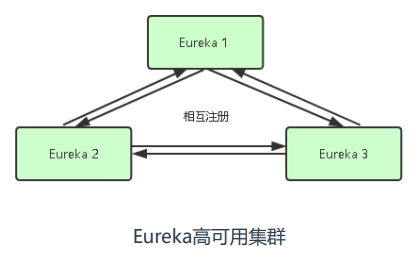
第五步:在K8s中部署Eureka集群(注册中心)和MySQL数据库
第六步:部署微服务网关服务
第七步:部署微服务业务程序
第八步:部署微服务前端
第九步:微服务对外发布
第十步:微服务升级与扩容
第一步:熟悉Spring Cloud微服务项目
https://gitee.com/lucky_liuzhe/simple-microservice
代码分支说明:
-
dev1 交付代码
-
dev2 增加Dockerfile
-
dev3 增加K8s资源编排
-
dev4 增加APM监控系统
-
master 最终上线
第二步:源代码编译构建
Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管 理工具软件。
yum install java-1.8.0-openjdk maven -y |
第三步:构建项目镜像并推送到镜像仓库

Dockerfile文件更换apk阿里云源
链接:https://blog.csdn.net/qq_33657251/article/details/107526842 |
第四步:K8s服务编排
第五步:在K8s中部署Erureka集群和MySQL数据库
1.删除Dockerfile中运行的拷贝时区的命令
find . -name Dockerfile | xargs -i sed -i '/RUN/d' {} |
2.修改源代码中eureka配置文件:
# cat eureka-service/src/main/resources/application-fat.yml |
prefer-ip-address: false 由于使用statefulset部署默认使用主机名通信,其他微服务使用deployment部署无法使用主机名通信,dns无法解析,所以修改为使用IP去通信。
Eureka集群节点Pod DNS名称:
http://eureka-0.eureka.ms.svc.cluster.local
http://eureka-1.eureka.ms.svc.cluster.local
http://eureka-2.eureka.ms.svc.cluster.local
3.修改docker_build.sh 文件
修改镜像仓库地址,要推送的镜像仓库项目名
#vi docker_build.sh |
4.创建命名空间并部署eureka服务并启动(记得部署之前要部署ingress控制器)
#创建命名空间 |
5.部署MySQL
#部署MySQL |
MySQL Service DNS名称:mysql.ms.svc.cluster.local
第六步至第九步:在K8s中部署微服务
-
部署业务程序(product、stock、order)
-
部署网关(gateway)
-
部署前端(portal)
修改product、stock、order连接数据库地址
#vi product-service/product-service-biz/src/main/resources/application-fat.yml |
启动部署
#修改各个微服务yaml文件中的requests,请求资源设置小一点0.2(java太吃内存) |
第十步:微服务升级与扩容
微服务升级:对要升级的微服务进行上述步骤打包镜像:版本,替代运行的镜像
微服务扩容:对Pod扩容副本数
kubectl scale deployment product --replicas=2 -n ms |
生产环境踩坑经验分享
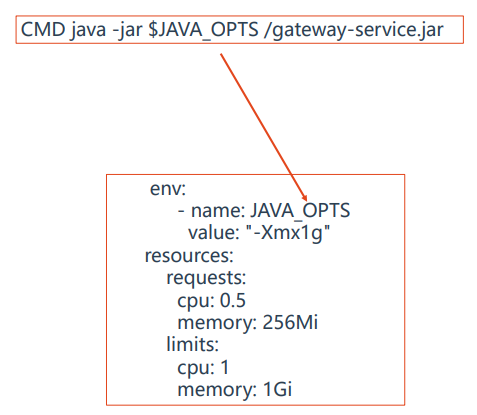
Q:限制了容器资源,还经常被杀死?
A:在JAVA1.9版本之前,是不能自动发现docker设置的 内存限制,随着应用负载起伏就会造成内存使用过大, 超过limits限制,从而触发K8s杀掉该容器。
解决办法:
-
手动指定JVM堆内存大小
-
配置JVM自动识别(1.9版本+才支持)-
XX:+UnlockExperimentalVMOptions -
XX:+UseCGroupMemoryLimitForHeap
Q:滚动更新期间造成流量丢失
A:滚动更新触发,Pod在删除过程中,有些节点kube-proxy还没来得及同步iptables规则, 从而部分流量请求到Terminating的Pod上,导致请求出错。
解决办法:配置preStop回调,在容器终止前优雅暂停5秒,给kube-proxy多预留一点时间。

Q:滚动更新之健康检查重要性
A:滚动更新是默认发布策略,当配置健康检查时,滚动更新会根据Probe状 态来决定是否继续更新以及是否允许接入流量,这样在整个滚动更新过程中可 保证始终会有可用的Pod存在,达到平滑升级。

APM监控微服务项目
微服务监控需求
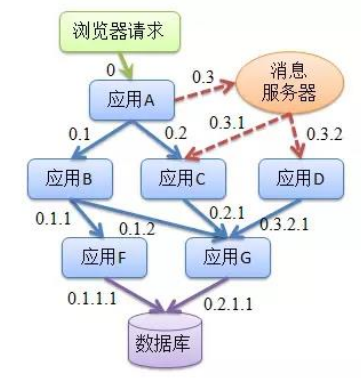
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要 涉及到多个服务。这些服务可能不同编程语言开发,不同团队开发,可能部 署很多副本。因此,就需要一些可以帮助理解系统行为、用于分析性能问题 的工具,以便发生故障的时候,能够快速定位和解决问题。“APM系统” 就 在这样的问题背景下产生了。
APM系统 从整体维度到局部维度展示各项指标,将跨应用的所有调用链性能 信息集中展现,可方便度量整体和局部性能,并且方便找到故障产生的源头, 生产上可极大缩短故障排除时间
APM监控系统是什么
APM(ApplicationPerformance Management)是一种应用性能监控工具,通过汇聚业务系统各处理 环节的实时数据,分析业务系统各事务处理的交易路径和处理时间,实现对应用的全链路性能监测。
相比接触的Prometheus、Zabbix这类监控系统,APM系统主要监控对应用程序内部,例如:
-
请求链路追踪:通过分析服务调用关系,绘制运行时拓扑信息,可视化展示
-
调用情况衡量:各个调用环节的性能分析,例如吞吐量、响应时间、错误次数
-
运行情况反馈:告警,通过调用链结合业务日志快速定位错误信息
APM监控系统选择依据
APM类监控系统有:Skywalking、Pinpoint、Zipkin
关于选型,可以从以下方面考虑:
探针的性能消耗
APM组件服务的影响应该做到足够小,数据分析要快,性能占用小。
代码的侵入性
即也作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用 方透明,减少开发人员的负担。
监控维度
分析的维度尽可能多。
可扩展性
一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够 支持的组件越多当然越好。
Skywalking介绍
Skywalking 是一个分布式应用程序性能监控系统,针对微服务体系结构而设计。
功能:
-
多种监控手段。可以通过语言探针和 service mesh 获得监控是数据。
-
多个语言自动探针。包括 Java,.NET Core 和 Node.JS。
-
轻量高效。无需大数据平台,和大量的服务器资源。
-
模块化。UI、存储、集群管理都有多种机制可选。
-
支持告警。
-
优秀的可视化解决方案。
Skywalking架构
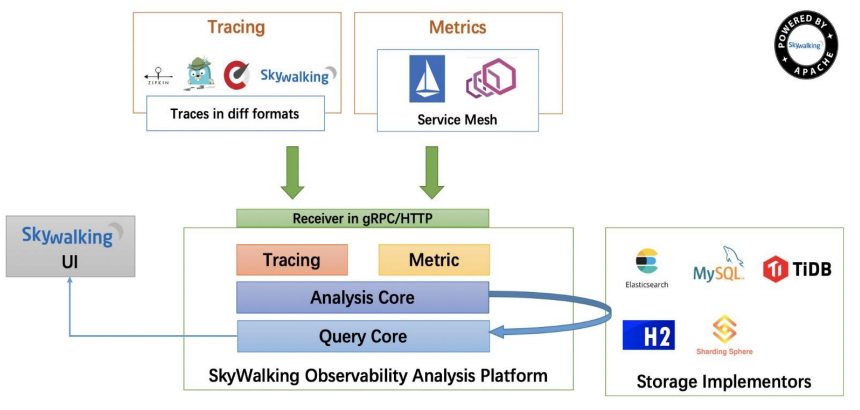
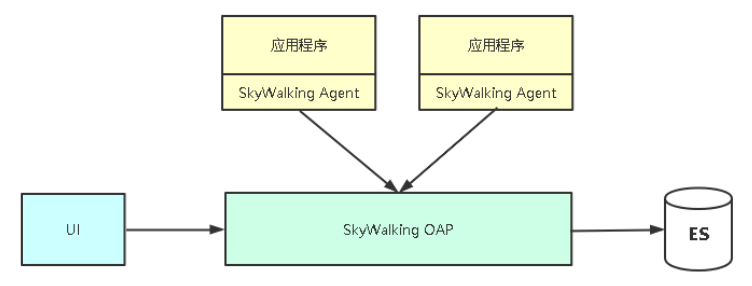
Skywalking部署
1、部署ES数据库
docker run --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" -d elasticsearch:7.7.0 |
2、部署Skywalking OAP
软件包下载地址:https://archive.apache.org/dist/skywalking/8.3.0/ |
指定数据源:
#vi config/application.yml |
启动OAP和UI:
./bin/startup.sh |
访问UI:http://IP:8080
微服务接入Skywalking监控
内置Agent包路径:apache-skywalking-apm-bin-es7/agent/
启动Java程序以探针方式集成Agent:
java -jar -javaagent:/skywalking/skywalking-agent.jar=agent.service_name=<项目名称 >,agent.instance_name=<实例名称>,collector.backend_service=:11800 xxx.jar
#使用dev4分支部署 |
Skywalking UI使用
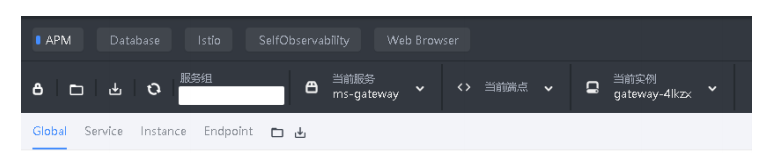
-
第一栏:不同内容主题的监控面板,应用/数据库/容器等
-
第二栏:操作,包括编辑/导出当前数据/倒入展示数据/不同服务端点筛选展示
-
第三栏:不同纬度展示,服务/实例/端点
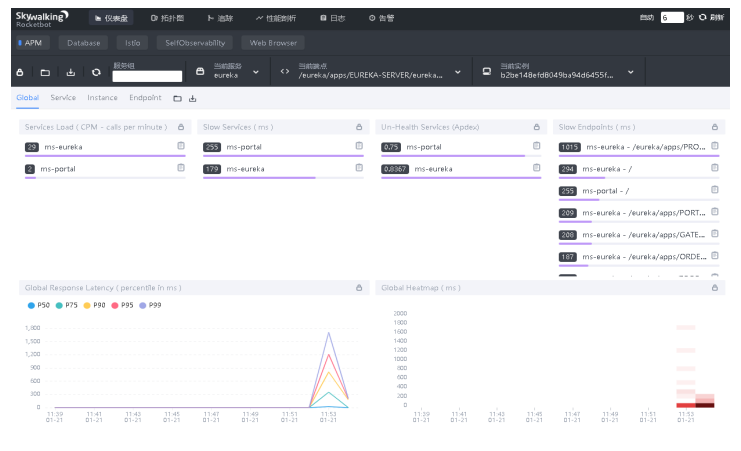
全局:
-
Service Load:CPM 每分钟回调次数
-
Slow Services:慢响应服务,单位ms
-
Un-Health Services:不健康的服务,1为满分
-
Slow Endpoints:慢端点,单位ms
-
Global Response Latency:百分比响应延时,不同百分 比的延时时间,单位ms
-
Global Heatmap:服务响应时间热力分布图,根据时间 段内不同响应时间的数量显示颜色深度
-
底部栏:展示数据的时间区间,点击可以调整
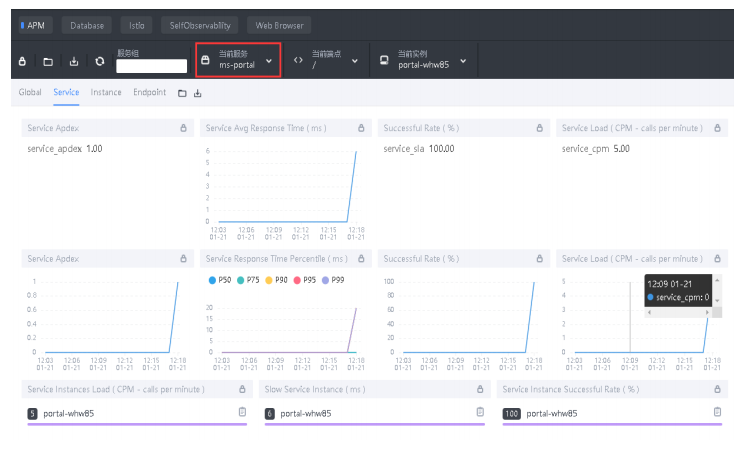
Service:
-
Service Apdex(数字):当前服务的评分
-
Service Apdex(折线图):当前服务评分趋势图
-
Service Avg Response Times:服务平均响应时间,单 位ms
-
Service Response Time Percentile:服务响应时间百分 比,单位ms
-
Successful Rate(数字):请求成功率
-
Successful Rate(折线图):请求成功率趋势图
-
Servce Load(数字):每分钟请求数
-
Servce Load(折线图):每分钟请求数趋势图
-
Servce Instances Load:服务实例的每分钟请求数
-
Slow Service Instance:慢服务实例,单位ms
-
Service Instance Successful Rate:服务实例成功率
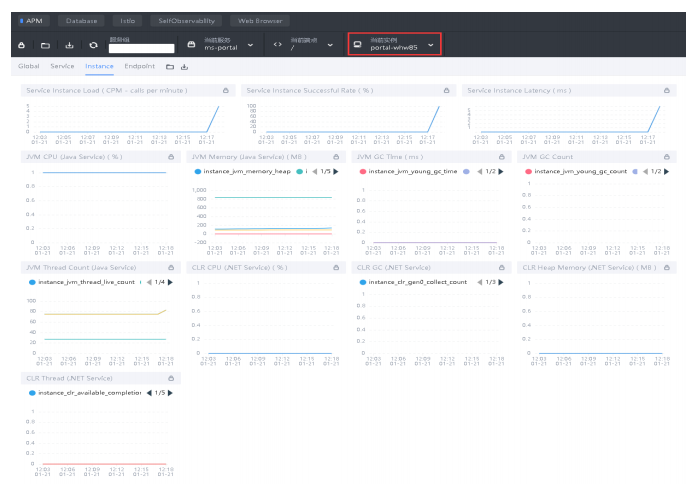
Instance:
-
Service Instance Load:当前实例的每分钟请求数
-
Service Instance Successful Rate:当前实例的请求成功率
-
Service Instance Latency:当前实例的响应延时
-
JVM CPU:jvm占用CPU的百分比
-
JVM Memory:JVM堆内存,单位MB
-
JVM GC Time:JVM垃圾回收时间,包含YGC和OGC
-
JVM GC Count:JVM垃圾回收次数,包含YGC和OGC
-
JVM Thread Count:JVM线程统计CLR XX:.NET服务的 指标,类似JVM虚拟机
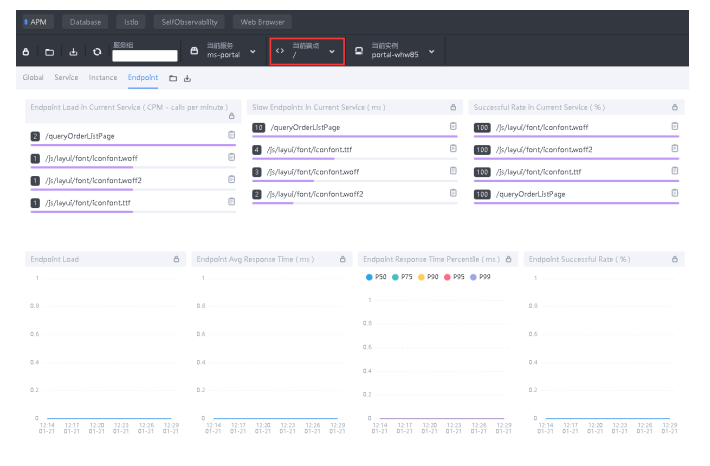
Instance:
-
Endpoint Load in Current Service:每个端点的每分钟请求数
-
Slow Endpoints in Current Service:每个端点的最慢请求时间, 单位ms
-
Successful Rate in Current Service:每个端点的请求成功率
-
Endpoint Load:端点请求数趋势图
-
Endpoint Avg Response Time:端点平均响应时间趋势图
-
Endpoint Response Time Percentile:端口响应时间的百分位数
-
Endpoint Successful Rate:端点请求成功率