Ceph分布式存储
Ceph概述
Ceph介绍
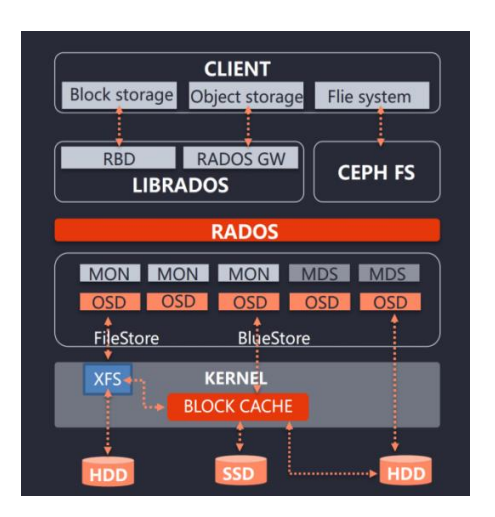
Ceph是一个开源的分布式存储系统,具有高扩展性、高性能、高可靠性等特点,提 供良好的性能、可靠性和可扩展性。支持对象存储、块存储和文件系统。 是目前为云平台提供存储的理想方案

Ceph架构
-
RBD(RADOS Block Device):块存储接口
-
RGW(RADOS Gateway)):对象存储网关,接口与S3和Swift兼容
-
CephFS(Ceph File System):文件级存储接口
-
RADOS(Reliable Autonomic Distributed Object Store):抽象的 对象存储集群,Ceph核心,实现用户数据分配、故障转移等集群操作
-
MON:集群状态维护,例如OSD是否健康、PG状态等
-
MDS (Metadata Server) :CephFS服务依赖的元数据服务
-
OSD(Object Storage Daemon):对象存储设备,主要存储数据
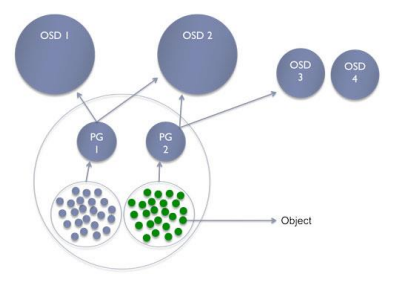
Ceph核心概念
Pool:存储池,是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本 分布策略;支持两种类型:副本(replicated)和 纠删码(Erasure Code)
PG( placement group):放置策略组,对象的集合,该集合里的所有对象都 具有相同的放置策略;简单点说就是相同PG内的对象都会放到相同的硬盘上; PG 是ceph的核心概念, 服务端数据均衡和恢复的最小粒度;引入PG这一层其实是为 了更好的分配数据和定位数据。
右边这张图描述了它们之间的关系:
-
一个Pool里有很多PG;
-
一个PG里包含一堆对象;一个对象只能属于一个PG;
-
PG属于多个OSD,分布在不同的OSD上;
部署Ceph集群
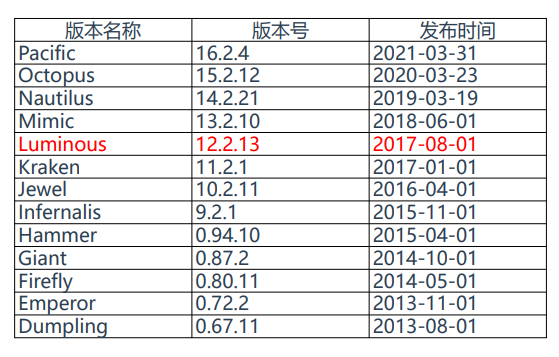
Ceph版本选择
Ceph目前最新版本16(P版),市面上应用最广泛的是12(L版)
参考:https://docs.ceph.com/en/latest/releases/
Ceph服务器配置推荐

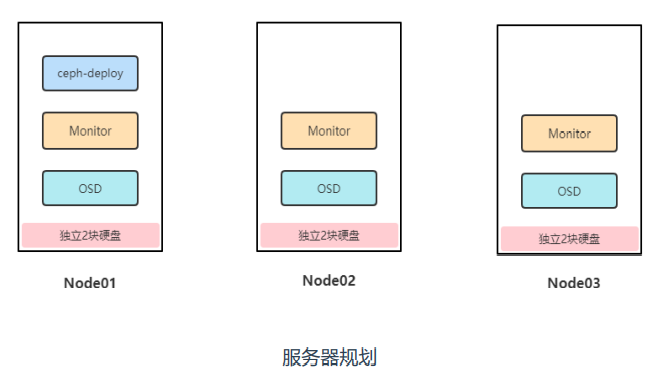
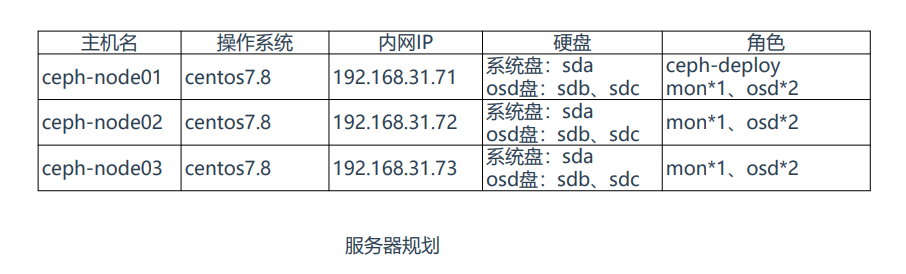
Ceph集群部署规划
-
ceph-deploy:ceph集群部署节点,负责集群整体部署, 这里复用node1节点,也可以单独找一台服务器作为部署 节点。
-
monitor:Ceph监视管理节点,承担Ceph集群重要的管 理任务,负责集群状态维护,例如存储池副本数、PG状 态、OSD数量等,至少部署1个,一般需要3或5个节点组 建高可用。
-
osd:Ceph存储节点,实际负责数据存储的节点,集群 中至少有3个OSD,不少于默认副本数,每个OSD对应一 块硬盘。
Ceph集群部署:操作系统初始化
ps:3台机器全部操作
关闭防火墙
systemctl stop firewalld |
关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久,重启生效 |
关闭swap
swapoff -a # 临时 |
根据规划设置主机名
hostnamectl set-hostname <hostname> |
在node添加hosts
cat >> /etc/hosts << EOF |
设置文件描述符
ulimit -SHn 102400 |
时间同步
yum install ntpdate -y |
配置SSH免交互认证
ssh-keygen -t rsa |
Ceph集群部署
Ceph集群部署方式:
-
yum:常规的部署方式
-
ceph-ansible:官方基于ansible写的自动化部署工具
https://docs.ceph.com/projects/ceph-ansible/en/latest/
- ceph-deploy:ceph提供的简易部署工具,可以非常方便部署ceph集群。(推荐)
https://docs.ceph.com/projects/ceph-deploy/en/latest/
Ceph集群部署步骤:
1、配置阿里云yum仓库 (所有节点安装)
cat > /etc/yum.repos.d/ceph.repo << EOF |
注:如果部署别的版本,将octopus替换为对应版本号即可。
2、安装ceph-deploy工具 (ceph-deploy节点安装)
yum -y install ceph-deploy |
3、创建集群 (ceph-deploy节点安装)
#创建一个my-cluster目录,所有命令在此目录下进行: |
4、安装Ceph (ceph-deploy节点安装)
#安装Ceph包到指定节点: |
5、部署Monitor服务 (ceph-deploy节点安装)
#初始化并部署monitor,收集所有密钥: |
6、部署OSD服务并添加硬盘 (ceph-deploy节点安装)
#创建6个OSD,分别对应每个节点未使用的硬盘: |
7、部署MGR服务(ceph-deploy节点安装)
ceph-deploy mgr create ceph-node01 ceph-node02 ceph-node03 |
注:MGR是Ceph L版本新增加的组件,主要作用是分担和扩展monitor的部分功能,减轻monitor的负担。 建议每台monitor节点都部署一个mgr,以实现相同级别的高可用。
查看Ceph集群状态:
ceph -s |

解决办法:(3台节点都操作)
#安装缺少的模块 |
查看Ceph版本:
ceph -v |
Ceph集群服务管理
1、启动所有守护进程
# systemctl restart ceph.target |
2、按类型启动守护进程
# systemctl restart ceph-osd@id |
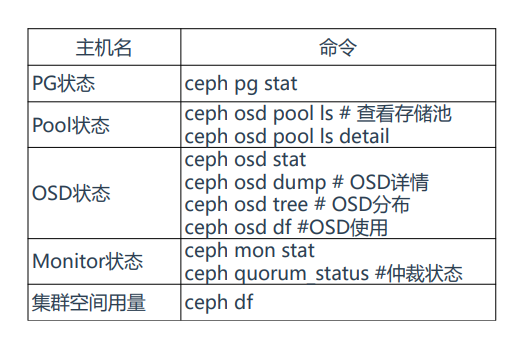
Ceph集群常用管理命令
Ceph存储使用
三种存储类型介绍
块存储(RBD)
优点:存储速度较快
缺点:不支持共享存储
应用场景:虚拟机硬盘
典型设备:硬盘、Raid
文件存储(CephFS)
优点:支持共享存储
缺点:读写速度较慢(需要经过操作系统处理再转为块存储)
应用场景:文件共享,多台服务器共享使用同一个存储
典型设备:FTP、NFS
对象存储(Object)
优点:具备块存储的读写性能和文件存储的共享特性
缺点:操作系统不能直接访问,只能通过应用程序级别的API访问
应用场景:图片存储,视频存储
典型设备:阿里云OSS,腾讯云COS
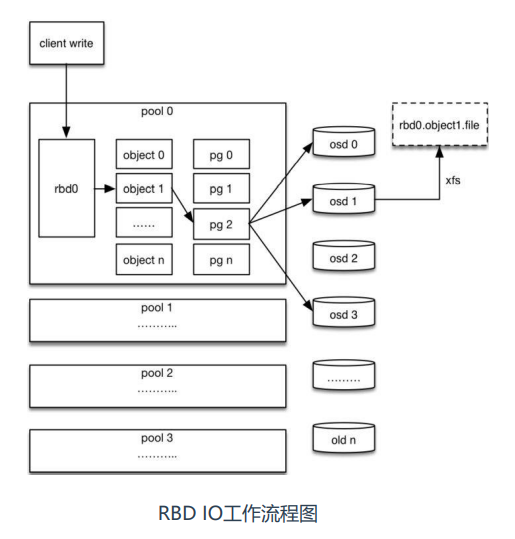
RBD块存储:RBD工作流程
1、客户端创建一个pool,并指定pg数量,创建rbd设备并挂载到文件系统;
2、用户写入数据,ceph进行对数据切块,每个块的大小默认为4M,每个 块名字是object+序号; 3、将每个object通过pg进行副本位置的分配;
4、pg根据crush算法会寻找3个osd,把这object分别保存在这3个osd上 存储;
5、osd实际把硬盘格式化为xfs文件系统,object存储在这个文件系统就相 当于存储了一个文件rbd0.object1.file。
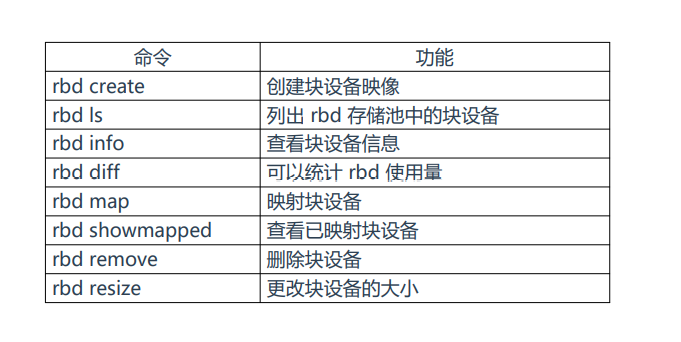
RBD块存储:常用管理命令
RBD块存储:RBD创建并使用
1、创建存储池
ceph osd pool create rbd-pool 128 # 格式:ceph osd pool create <pool-name> <pg-num> |
PG数量设置计算公式:PG数量=(OSD数量*100)/副本数(3)
例如我们的环境:(6*100)/3=200,一般设置是结果向上取2的N次方,所以pool指定的pg数量就是256
2、指定存储池使用存储类型
ceph osd pool application enable rbd-pool rbd |
3、创建一个10G的块设备
rbd create --size 10240 rbd-pool/image01 # 格式:rbd create --size {megabytes} {pool-name}/{image-name} |
4、查看块设备
rbd ls rbd-pool |
节点本地挂载使用块设备:
1、映射
rbd map rbd-pool/image01 |
2、格式化块设备
mkfs.xfs /dev/rbd0 |
3、挂载
mount /dev/rbd0 /mnt |
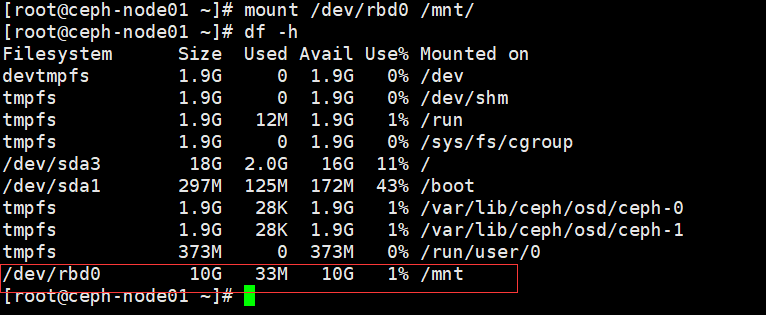
4、取消挂载和内核映射
umount /mnt |
远程挂载使用块设备:
1、拷贝配置文件和秘钥
cd my-cluster/ |
2、安装Ceph客户端
yum install epel-release -y |
3、剩余操作就与上面一样了
rbd create --size 20480 rbd-pool/image02 |
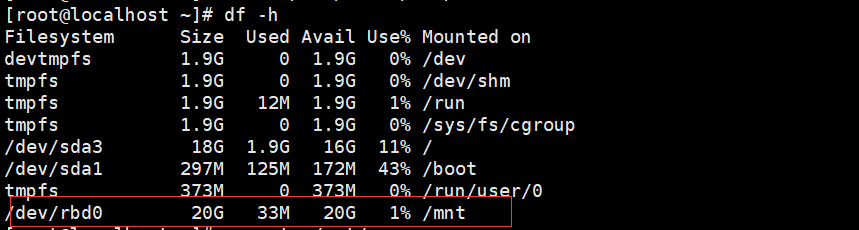
RBD块存储:快照
快照:在某个时间点的副本,当系统出现问题,可以通过恢复快照恢复之前副本状态。
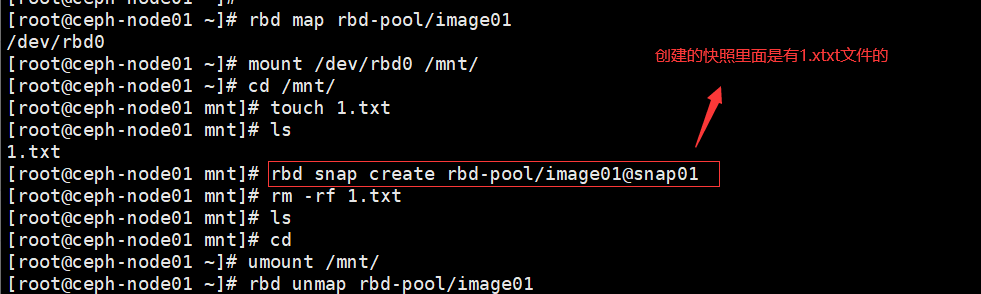
1、创建快照
rbd snap create rbd-pool/image01@snap01 |
2、查看快照
rbd snap list rbd-pool/image01 |
3、还原快照
umount /mnt/ |
4、重新映射并挂载验证
rbd map rbd-pool/image01 |
5、删除快照
rbd snap rm rbd-pool/image01@snap01 |

RBD块存储:克隆
克隆:基于指定的块设备克隆出相同的一份出来
1、创建一个块设备
rbd create --size 10240 rbd-pool/image02 |
2、创建快照
rbd snap create rbd-pool/image02@snap01 |
3、设置快照处于被保护状态
rbd snap protect rbd-pool/image02@snap01 |
4、通过快照克隆一个新块设备
rbd clone rbd-pool/image02@snap01 rbd-pool/image02_clone |
5、将克隆的块设备独立于父块设备
rbd flatten rbd-pool/image02_clone |
基于上述快照之后的步骤
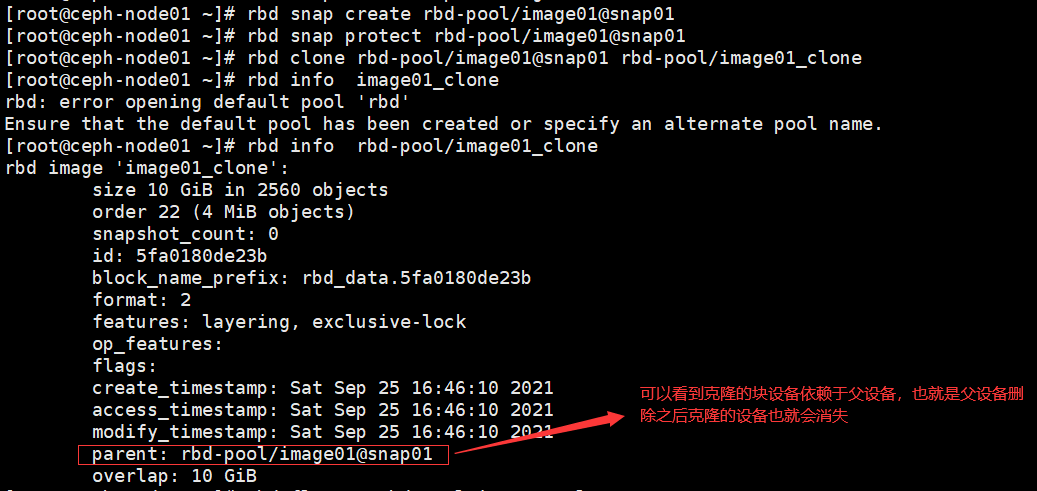
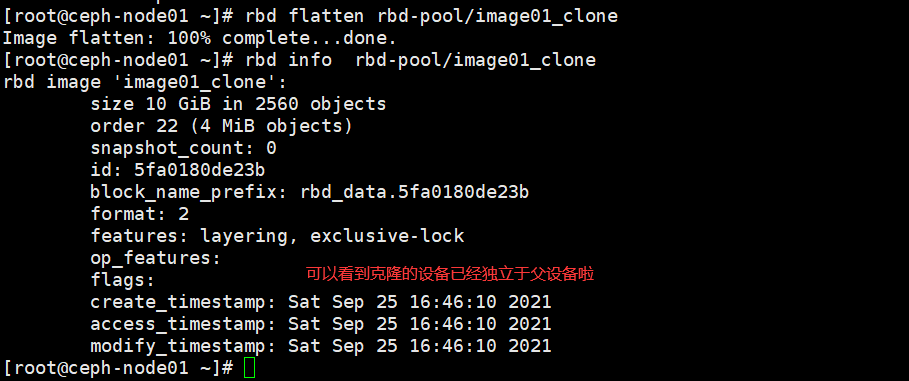
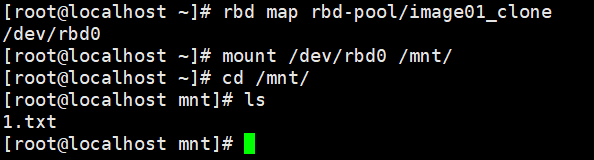
由于克隆的uuid一致,需要在其他机器上挂载验证克隆的镜像是否可用
CephFS文件系统
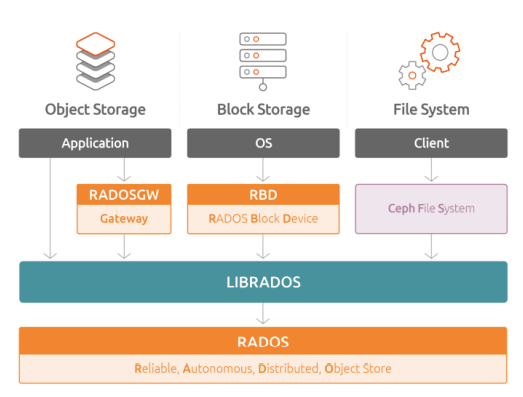
CephFS 是一个基于 ceph 集群且兼容POSIX标准的文件系统。
创建 cephfs 文件系统时需要在 ceph 集群中添加 mds 服务,该服务 负责处理 POSIX 文件系统中的 metadata 部分,实际的数据部分交由 ceph 集群中的OSD处理。
cephfs 支持以内核模块方式加载也支持 fuse 方式加载。无论是内核 模式还是 fuse 模式,都是通过调用 libcephfs 库来实现 cephfs 文件 系统的加载,而 libcephfs 库又调用 librados 库与 ceph 集群进行通 信,从而实现 cephfs 的加载。
CephFS文件系统:部署MDS服务
部署MDS实例:
ceph-deploy mds create ceph-node01 ceph-node02 ceph-node03 |
CephFS文件系统:创建文件系统
1、创建存储池
ceph osd pool create cephfs_data <pg_num> |
2、创建文件系统
ceph fs new cephfs cephfs_metadata cephfs_data # 格式:ceph fs new <fs_name> <metadata> <data> |
CephFS文件系统:挂载并使用
内核模块方式挂载:
1、安装Ceph客户端 (前面已经安装客户端啦)
yum install epel-release -y |
2、获取账号名与秘钥
ceph auth list |grep admin -A1 |
3、挂载本地目录
mount -t ceph 192.168.0.11:6789,192.168.0.12:6789,192.168.0.13:6789:/ /mnt/ -o name=admin,secret=AQDPhU5hxkfUHRAAQUcQHyrXTTJCRmBPONmVzg== |
4、取消挂载
umount /mnt |
fuse方式挂载:
1、安装fuse
yum install -y ceph-fuse |
2、挂载本地目录
ceph-fuse -m 192.168.0.11:6789,192.168.0.12:6789,192.168.0.13:6789 /mnt/ |
3、取消卸载
fusermount -u /mnt/ |
对象存储
Ceph对象存储不能像RBD、CephFS那样方式访问,它是通 过Restfulapi方式进行访问和使用。兼容S3/Swift接口,由 radosgw组件提供服务。所以需要安装这个服务。
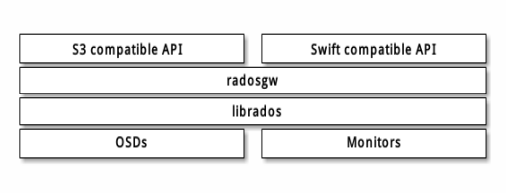
对象存储:部署RGW服务
部署RGW服务:
ceph-deploy rgw create ceph-node01 ceph-node02 |
验证访问,RGW默认7480端口,浏览器访问:http://192.168.31.71:7480
返回anonymous说明服务正常。
对象存储:使用
radosgw-admin 是 RADOS 网关用户管理工具。
1、创建S3账号
radosgw-admin user create --uid="azhe" --display-name="azhe" |
2、编写Python脚本测试
安装连接boto模块,用于连接S3接口: |
Kubernetes使用Ceph作为Pod存储
PV与PVC概述
PersistentVolume(PV):持久卷,对外部存储资源创建和使用的抽象, 使得存储作为集群中的资源管理;PV又分为静态供给和动态供给,由于静态 供给需要提前创建一堆PV,维护成本较高,所以企业一般使用动态供给。
PersistentVolumeClaim(PVC):持久卷申请,让用户不需要关心具体 的Volume实现细节,只需要定义PVC需要多少磁盘容量即可。
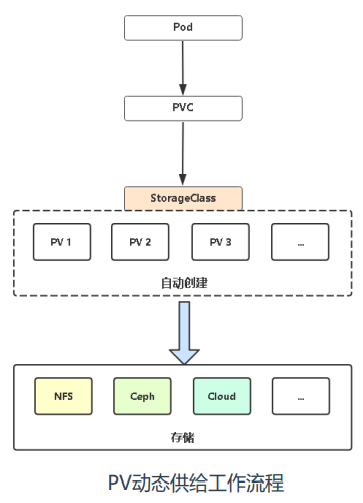
ceph-csi供给程序
ceph-csi是ceph官方维护的PV供给程序,专门用于在 Kubernetes中使用RBD、CephFS为Pod提供存储。
项目地址:https://github.com/ceph/ceph-csi
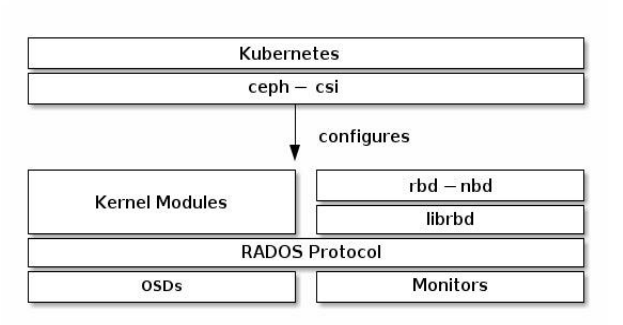
Pod使用RBD块存储
关于部署,RBD YAML文件在deploy/rbd/kubernetes目录,课件中YAML改动如下:
-
全部统一命名空间到ceph-csi
-
将镜像转存到docker hub
-
增加secret.yaml和storageclass.yaml文件
-
将csi-rbdplugin-provisioner.yaml 和 csi-rbdplugin.yaml 中 关于kms配置注释
在使用中,还需要根据自己集群环境修改:
-
csi-config-map.yaml 修改连接ceph集群信息
-
secret.yaml 修改秘钥
-
storageclass.yaml 修改集群ID和存储池
Pod使用CephFS文件系统
关于部署,RBD YAML文件在deploy/cephfs/kubernetes目录,课件中YAML改动如下:
-
全部统一命名空间到ceph-csi-cephfs
-
将镜像转存到docker hub
-
增加secret.yaml和storageclass.yaml文件
-
将csi-rbdplugin-provisioner.yaml 和 csi-rbdplugin.yaml 中 关于kms配置注释
在使用中,还需要根据自己集群环境修改:
-
csi-config-map.yaml 修改连接ceph集群信息
-
secret.yaml 修改秘钥
-
storageclass.yaml 修改集群ID和文件系统名称
小结
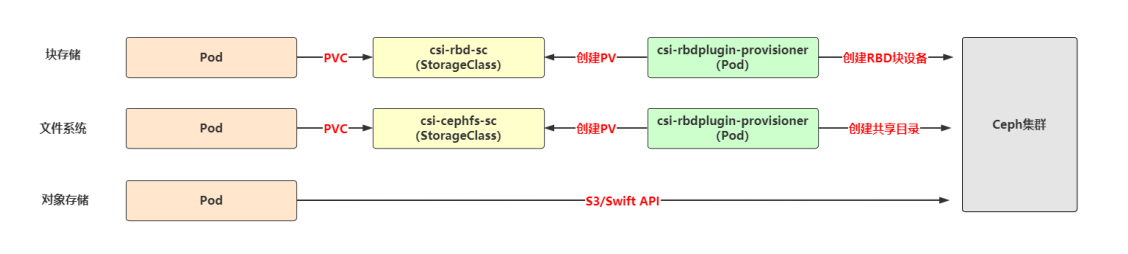
RBD:
优点:读写性能好,支持镜像快照、克隆
缺点:不支持多节点挂载
适用场景:对读写性能要求高,且无多节点同时读写数据需求的应用,例如数据库
CephFS:
优点:支持K8s所有访问模式,支持多节点同时读写数据
缺点:读写性能一般,延迟时间不稳定
适用场景:对读写性能要求不高,I/O延迟不敏感的应用,例如文件共享
Ceph 监控
Dashboard
从L版本开始,Ceph 提供了原生的Dashboard功能,通过Dashboard对Ceph集群状态查看和基本管理。
使用Dashboard需要在MGR节点安装软件包: yum install ceph-mgr-dashboard –y
如果是按课程用的O版本会出现下面缺少依赖包提示:
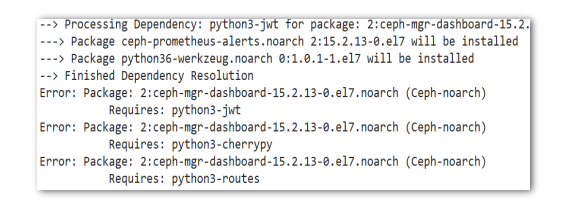
原因分析:这是由于从O版本开始,MGR改为Python3编写,而默认库没有这3个模块包,即使单独找包安装也可能 不生效或者安装不上。从社区得知,这是已知问题,建议使用CentOS8系统或者使用cephadm容器化部署Ceph。 或者降低Ceph版本也可以,例如H版本,这个版本还是Python2编写的,不存在缺包问题。
这里选择降低到H版本,重新部署Ceph集群。
1、清理Ceph集群环境
# 从远程主机卸载ceph包并清理所有数据 |
2、与之前部署方式一样
cat > /etc/yum.repos.d/ceph.repo << EOF |
yum -y install ceph-deploy |
3、添加RBD块设备和CephFS文件系统测试
添加RBD块设备:
ceph osd pool create rbd-pool 128 |
添加CephFS文件系统:
ceph-deploy mds create ceph-node01 ceph-node02 ceph-node03 |
1、在每个MGR节点安装
yum install ceph-mgr-dashboard –y |
2、开启MGR功能
ceph mgr module enable dashboard |
3、修改默认配置
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0 |
4、创建一个dashboard登录用户名密码
ceph dashboard ac-user-create admin administrator -i password.txt |
5、查看服务访问方式
ceph mgr services |
后面如果修改配置,重启生效:
ceph mgr module disable dashboard |
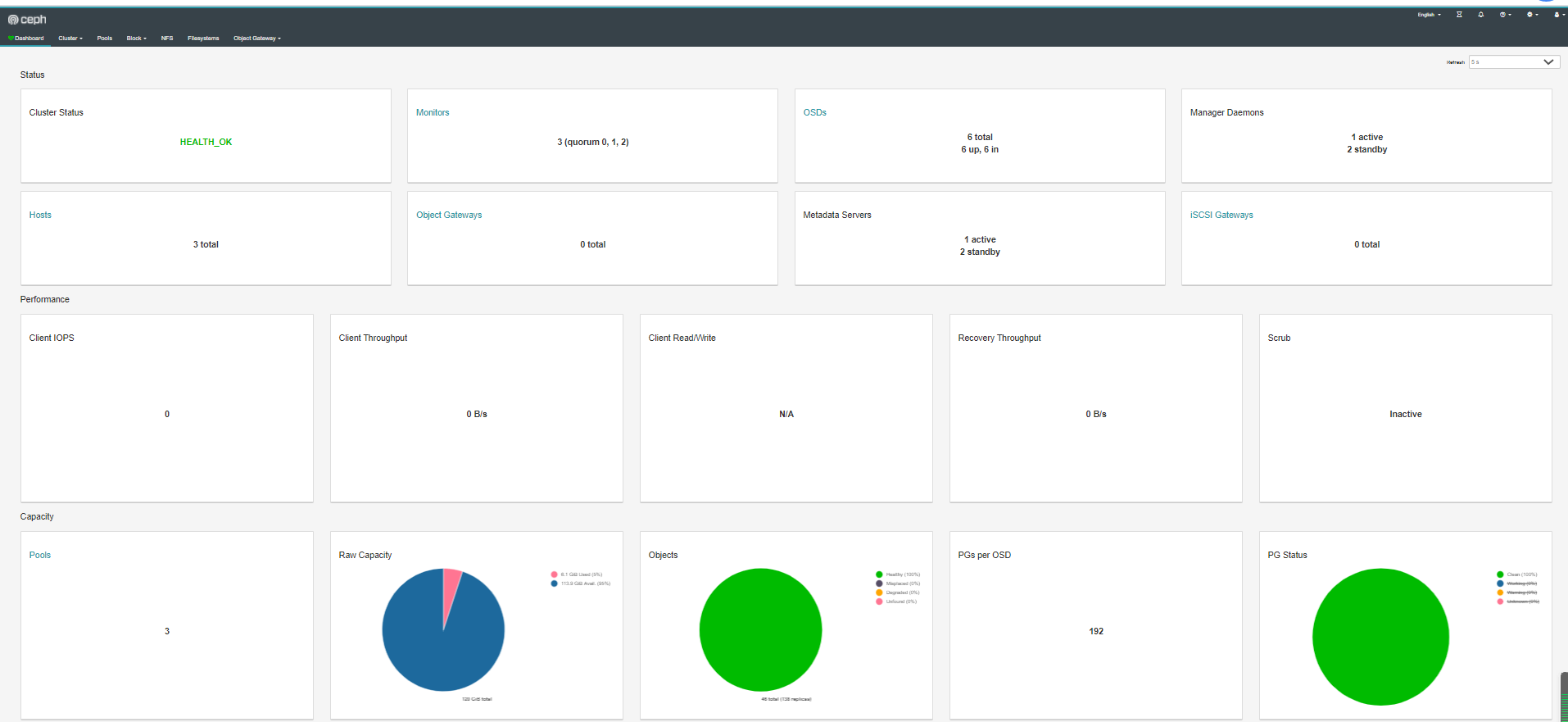
Prometheus+Grafana监控Ceph
- Prometheus(普罗米修斯):容器监控系统。
- Grafana:是一个开源的度量分析和可视化系统。
官网:https://grafana.com/grafana
1、Docker部署Prometheus+Grafana
wget http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo |
2、启用MGR Prometheus插件
ceph mgr module enable prometheus |
3、配置Prometheus采集
docker exec -it prometheus sh |
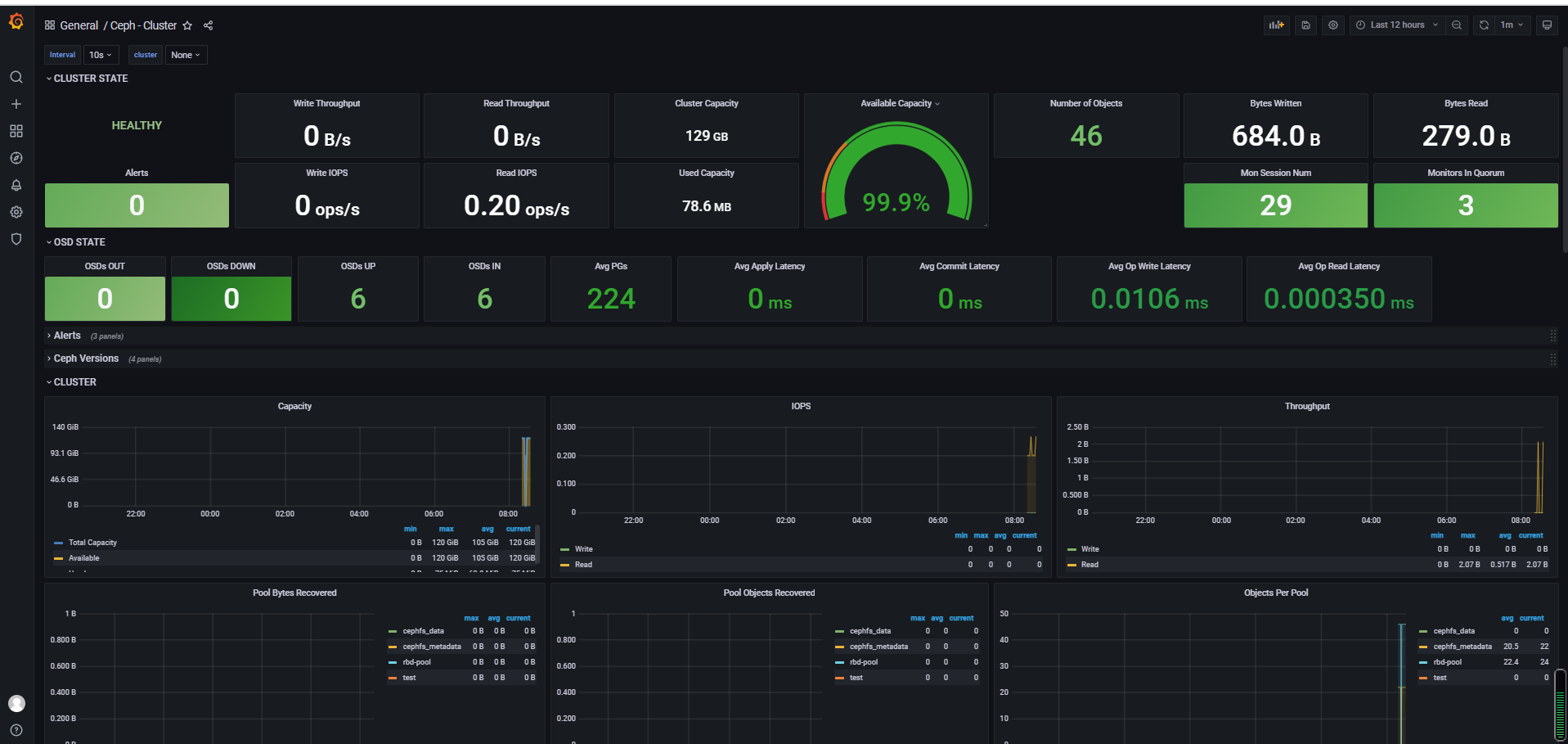
4、访问Grafana仪表盘
默认用户名密码均为admin
-
添加Prometheus为数据源:Configuration -> Data sources -> Promethes -> 输入URL http://IP:9090
-
导入Ceph监控仪表盘:Dashboards -> Manage -> Import -> 输入仪表盘ID,加载
-
Ceph-Cluster ID:2842
-
Ceph-OSD ID:5336
-
Ceph-Pool ID:5342