
K8s集群网络下
K8s网络组件之Calico
Calico是一个纯三层的数据中心网络方案,Calico支持广泛的平台,包括Kubernetes、OpenStack等。 Calico 在每一个计算节点利用 Linux Kernel 实现了一个高效的虚拟路由器( vRouter) 来负责数据转发, 而每个 vRouter 通过 BGP 协议负责把自己上运行的 workload 的路由信息向整个 Calico 网络内传播。 此外,Calico 项目还实现了 Kubernetes 网络策略,提供ACL功能。
实际上,Calico项目提供的网络解决方案,与Flannel的host-gw模式几乎一样。也就是说,Calico也是基于 路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用 BGP协议来自动维护整个集群的路由信息。
BGP英文全称是Border Gateway Protocol,即边界网关协议,它是一种自治系统间的动态路由发现协议, 与其他 BGP 系统交换网络可达信息。
K8s网络组件之Calico:BGP介绍
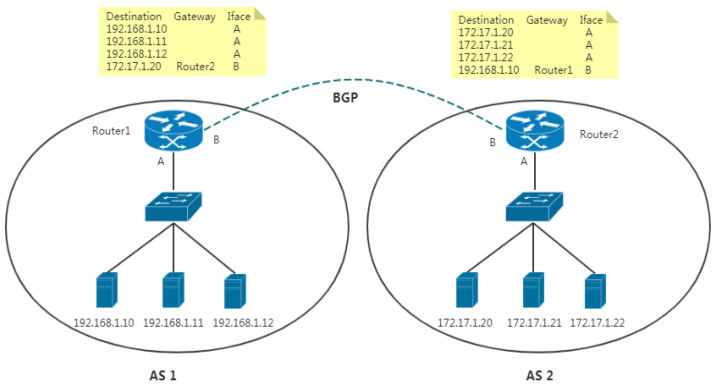
在这个图中,有两个自治系统(autonomous system,简称为AS):AS 1 和 AS 2。
在互联网中,一个自治系统(AS)是一个有权自主地决定在本系统中应采用何种路由协议的小型单位。这 个网络单位可以是一个简单的网络也可以是一个由一个或多个普通的网络管理员来控制的网络群体,它 是一个单独的可管理的网络单元(例如一所大学,一个企业或者一个公司个体)。一个自治系统有时也 被称为是一个路由选择域(routing domain)。一个自治系统将会分配一个全局的唯一的16位号码, 有时我们把这个号码叫做自治系统号(ASN)。
在正常情况下,自治系统之间不会有任何来往。如果两个自治系统里的主机,要通过 IP 地址直接进行通 信,我们就必须使用路由器把这两个自治系统连接起来。BGP协议就是让他们互联的一种方式。
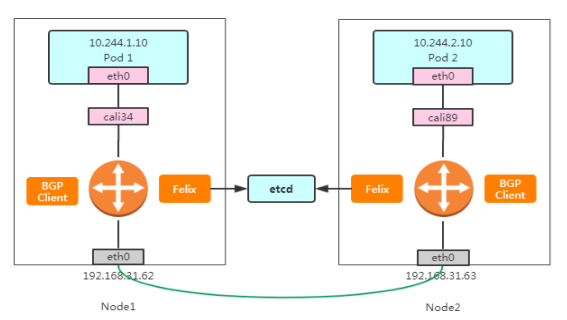
在了解了 BGP 之后,Calico 项目的架构就非常容易理解了,
Calico主要由三个部分组成:
-
Felix:以DaemonSet方式部署,运行在每一个Node节点上, 主要负责维护宿主机上路由规则以及ACL规则。
-
BGP Client(BIRD):主要负责把 Felix 写入 Kernel 的路 由信息分发到集群 Calico 网络。
-
Etcd:分布式键值存储,保存Calico的策略和网络配置状态。
-
calicoctl:命令行管理Calico。
K8s网络组件之Calico:部署
Calico存储有两种方式:
- 数据存储在etcd
https://docs.projectcalico.org/v3.9/manifests/calico-etcd.yaml
- 数据存储在Kubernetes API Datastore服务中
https://docs.projectcalico.org/manifests/calico.yaml
数据存储在etcd中还需要修改yaml:
- 配置连接etcd地址,如果使用https,还需要配置证书。(ConfigMap和Secret位置)

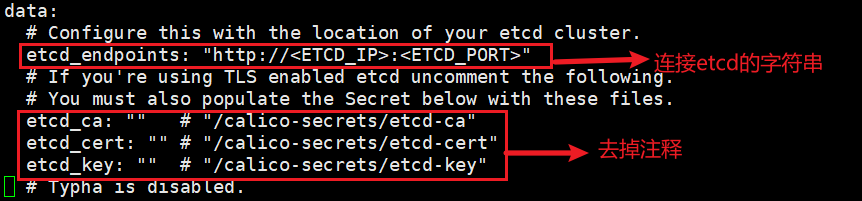
根据实际网络规划修改Pod CIDR(CALICOIPV4POOLCIDR)(两种方式都需要修改)
部署:
# kubectl apply -f calico.yaml |
K8s网络组件之Calico:管理工具
calicoctl工具用于管理calico,可通过命令行读取、创建、更新和删除 Calico 的存储对象。
项目地址:https://github.com/projectcalico/calicoctl
calicoctl 在使用过程中,需要从配置文件中读取 Calico 对象存储地址等信息。默认配置文件路 径 /etc/calico/calicoctl.cfg
方式1(基于ectd存储):
#使用calicoctl命令 |
方式2(基于kubernetes API Datastore存储):
#配置calicoctl配置文件 |
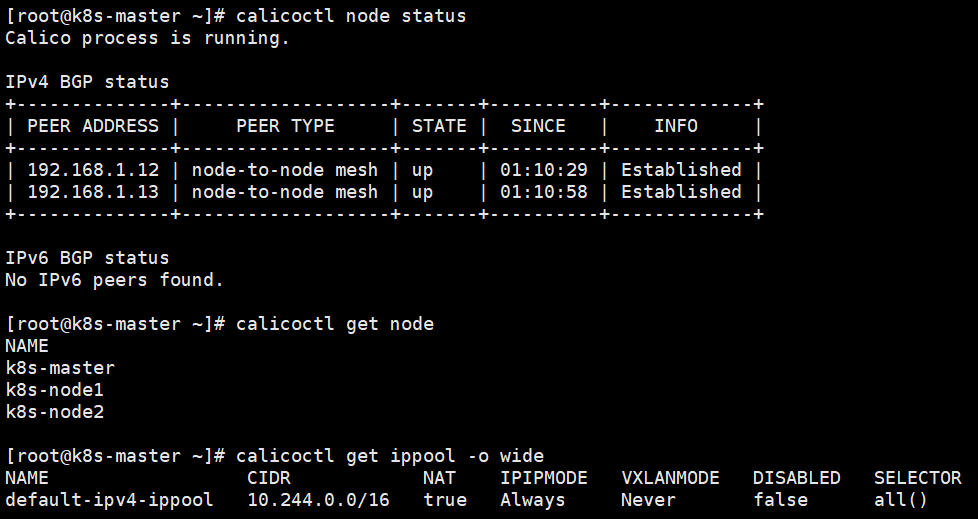
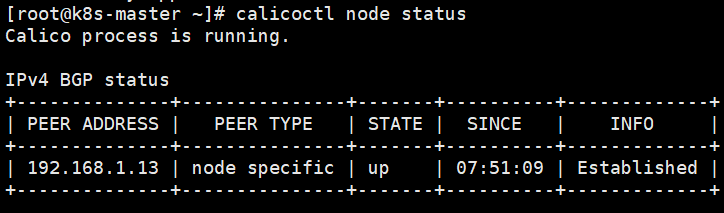
查看Calico状态:
calicoctl node status |
K8s网络组件之Calico:工作模式
Calico工作模式:
-
IPIP:Overlay Network方案,源数据包封装在宿主机网络包里进行转发和通信。(默认)
-
BGP:基于路由转发,每个节点通过BGP协议同步路由表,写到宿主机。 (值设置Never)
-
CrossSubnet:同时支持BGP和IPIP,即根据子网选择转发方式。
通过调整参数改变工作模式:
-
name: CALICO_IPV4POOL_IPIP
value: “Always”
K8s网络组件之Calico:IPIP工作模式
IPIP模式:采用Linux IPIP隧道技术实现的数据包封装与转发。
IP 隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,Linux系统内核实现的
IP隧道技术主要有三种:IPIP、GRE、SIT。
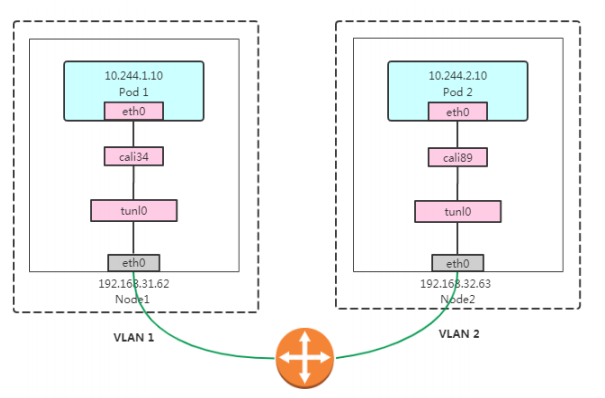
Pod 1 访问 Pod 2 大致流程如下:
-
数据包(原始数据包)从容器出去到达宿主机,宿主机根据路由表发送到tunl0设备(IP隧道设备)
-
Linux内核IPIP驱动将原始数据包封装在宿主机网络的IP包中(新的IP包目的地之是原IP包的下一跳地 址,即192.168.31.63)。
-
数据包根据宿主机网络到达Node2;
-
Node2收到数据包后,使用IPIP驱动进行解包,从中拿到原始数据包;
-
然后根据路由规则,根据路由规则将数据包转发给cali设备,从而到达容器2。
K8s网络组件之Calico:BGP工作模式
BGP模式:基于路由转发,每个节点通过BGP协议同步路由 表,将每个宿主机当做路由器,实现数据包转发。
calicoctl工具修改为BGP模式:
calicoctl get ippool -o yaml >ippool.yaml |
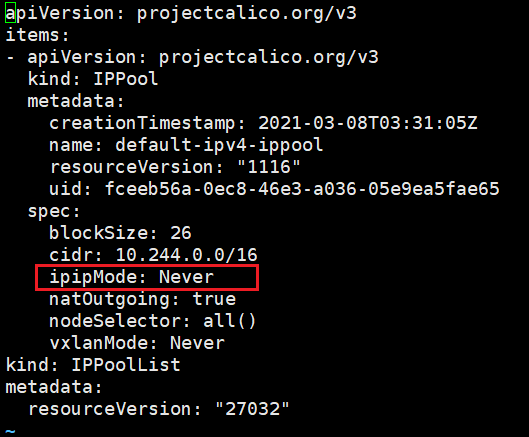
calicoctl apply -f ippool.yaml |

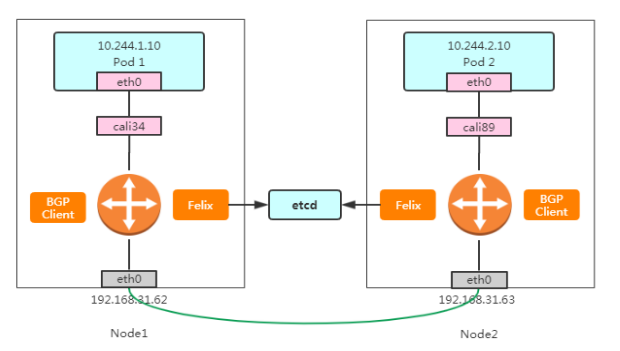
Pod 1 访问 Pod 2 大致流程如下:
-
数据包从容器出去到达宿主机;
-
宿主机根据路由规则,将数据包转发给下一跳(网关);
-
到达Node2,根据路由规则将数据包转发给cali设备,从而到达容器2。
K8s网络组件之Calico:Route Reflector 模式(RR)
Calico 维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由 交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加,就会产生性能问题。
这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
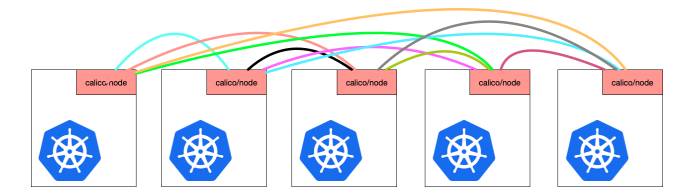
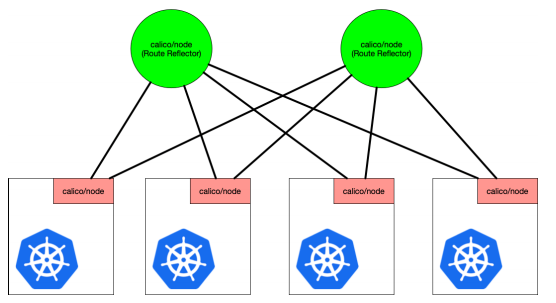
确定一个或多个Calico节点充当路由反射器,集中分发路由,让其 他节点从这个RR节点获取路由信息。
具体步骤如下:
1、关闭 node-to-node模式
添加 default BGP配置,调整 nodeToNodeMeshEnabled和asNumber:
#ASN号可以通过获取 |
2、配置指定节点充当路由反射器
为方便让BGPPeer轻松选择节点,通过标签选择器匹配。 给路由器反射器节点打标签:
#kubectl label node k8s-node2 route-reflector=true |
然后配置路由器反射器节点routeReflectorClusterID
#calicoctl get node k8s-node2 -o yaml > rr-node.yaml |
3、使用标签选择器将路由反射器节点与其他非路由反射器节点配置为对等
#vi bgppeer.yaml |
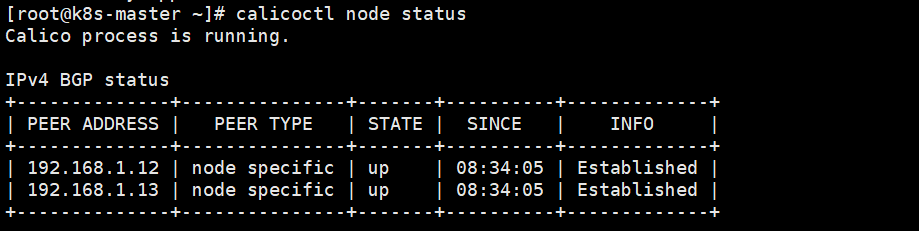
配置多个节点充当路由反射器
1.给路由器反射器节点打标签:
kubectl label node k8s-node1 route-reflector=true |
然后配置路由器反射器节点routeReflectorClusterID:
calicoctl get node k8s-node1 -o yaml > rr-node.yaml |
2.重新应用bgppeer.yaml
calicoctl delete -f bgppeer.yaml |

小结
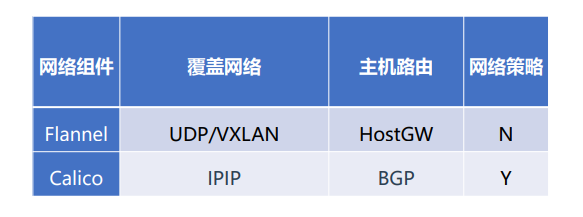
网络性能:首选路由方案 flannel组件的hostGW和calico的BGP
集群规划:100+建议calico
网络限制:不能跑BGP
是否需要网络策略?
VXLAN和IPIP模式:
优势:只要你的集群节点之间互相能通信就行,不管你宿主机走的是二层还是三层。
缺点:先进行二层帧封装,再通过宿主机网络封装,解封装也一样,所以增加性能开销
HostGW和BGP模式:
优势:由于走的是宿主机网络路由,性能开销小
缺点:对宿主机网络要求二层可达,想要实现宿主机之前跨网段通信,需要同步宿主机路由信息到上层路由器。flannel需要手动同步,calico使用BGP动态路由发现协议自动同步,只要上层路由支持BGP协议。
办公网络与K8s网络互通方案
网络需求:
-
办公网络与Pod网络不通。在微服务架构下,开发人员希望在办公电脑能 直接连接K8s中注册中心调试;
-
办公网络与Service网络不通。在测试环境运行的mysql、redis等需要通过 nodeport暴露,维护成本大;
-
现有虚拟机业务访问K8s上的业务。
解决方案:打通办公网络与K8s网络
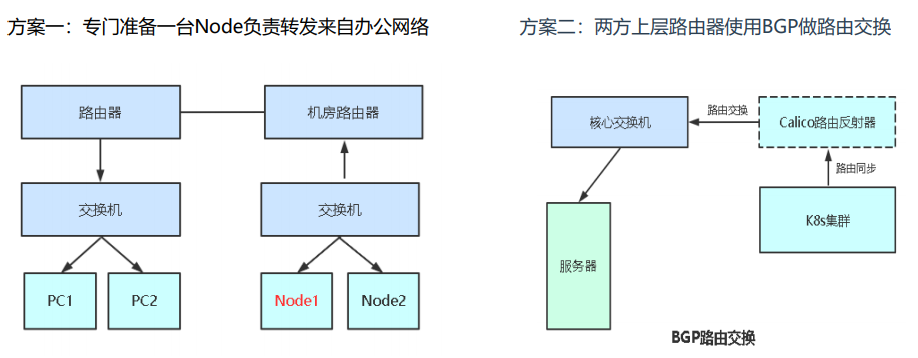
方案一:在办公室网络上层路由器添加一条静态路由条目,目标网段是容器网络(10.244.0.0)下一跳地址设置为某个node节点IP,从路由器的一个接口出,到达node节点上后,配置iptables规则源网段是办公室网段IP(192.168.0.0)转发到pod网段IP(10.244.0.0),还有源网段是办公室网段IP转发到service网段IP(10.96.0.0/12)。
方案二:服务器的上层核心交换机和k8s集群的上层路由反射器通过BGP协议相互学习对方的路由,从而实现路由的互通。
网络策略概述
网络策略(Network Policy),用于限制Pod出入流量,提供Pod级别和Namespace级别网络访问控制。 一些应用场景:
-
应用程序间的访问控制。例如微服务A允许访问微服务B,微服务C不能访问微服务A
-
开发环境命名空间不能访问测试环境命名空间Pod
-
当Pod暴露到外部时,需要做Pod白名单
-
多租户网络环境隔离
Pod网络入口方向隔离:
-
基于Pod级网络隔离:只允许特定对象访问Pod(使用标签定义),允许白名单上的IP地址或者IP段访问Pod
-
基于Namespace级网络隔离:多个命名空间,A和B命名空间Pod完全隔离。
Pod网络出口方向隔离:
-
拒绝某个Namespace上所有Pod访问外部
-
基于目的IP的网络隔离:只允许Pod访问白名单上的IP地址或者IP段
-
基于目标端口的网络隔离:只允许Pod访问白名单上的端口
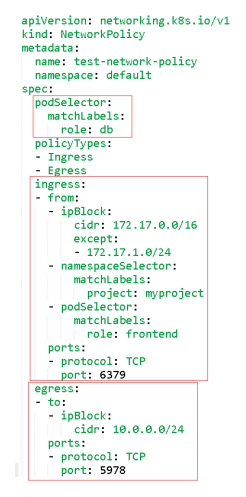
podSelector:目标Pod,根据标签选择
policyTypes:策略类型,指定策略用于入站、出站流量。
Ingress:from是可以访问的白名单,可以来自于IP段、命名空间、 Pod标签等,ports是可以访问的端口。
Egress:这个Pod组可以访问外部的IP段和端口。
案例:对项目Pod出入流量访问控制
需求1:将default命名空间携带app=web标签的Pod隔离,只允 许default命名空间携带run=client1标签的Pod访问80端口。
准备测试环境:
kubectl create deployment web --image=nginx |
#vi np.yaml |
验证结果:client1pod可以下载web的首页,client2pod不可以下载web的首页
需求2:default命名空间下所有pod可以互相访问,也可以访问其 他命名空间Pod,但其他命名空间不能访问default命名空间Pod。
-
podSelector: {}:如果未配置,默认所有Pod
-
from.podSelector: {} : 如果未配置,默认不允许
kubectl run client3 --image=busybox -n azhe -- sleep 36000 |
验证结果:azhe命名空间下的client3pod不可以访问default命名空间下的pod,但default命名空间下的pod可以访问azhe命名空间下的pod。
网络策略实现流程
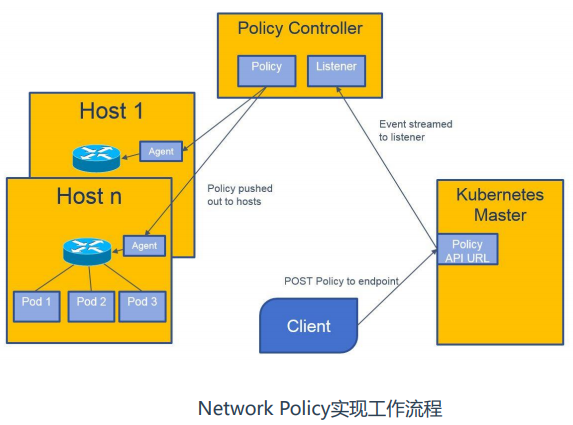
当我们创建一个网络策略,也就是apply 一个yaml文件,它会提交到apiserver,policy controller控制器(calico-kube-controllers)里面的进程会实时监听apiserver上的网络策略,拿到之后会通知它的agent(也就是运行在每个节点上calico pod(calico-node)来取我拿到的网络策略,然后在本地运行,calico-node利用iptables创建相应的网络规则。