
Prometheus+Grafana监控Kubernetes
Prometheus 介绍
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目, 拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基 金会(CNCF),成为继Kubernetes之后的第二个托管项目。
Prometheus组件与架构
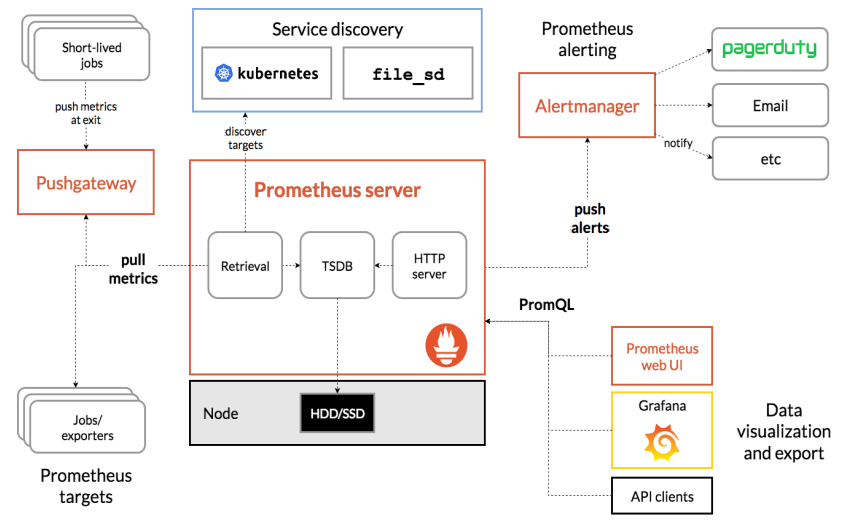
-
Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
-
ClientLibrary:客户端库
-
Push Gateway:短期存储指标数据。主要用于临时性的任务
-
Exporters:采集已有的第三方服务监控指标并暴露metrics
-
Alertmanager:告警
-
Web UI:简单的Web控制台
Prometheus基本使用:怎么来监控?
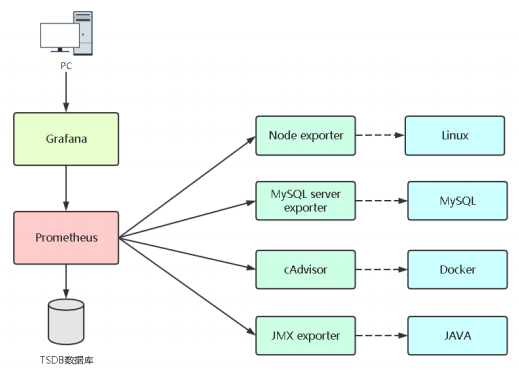
如果要想监控,前提是能获取被监控端指标数据,并且这个 数据格式必须遵循Prometheus数据模型,这样才能识别和 采集,一般使用exporter提供监控指标数据
exporter列表:
https://prometheus.io/docs/instrumenting/exporters
-
Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
-
ClientLibrary:客户端库
-
Push Gateway:短期存储指标数据。主要用于临时性的任务
-
Exporters:采集已有的第三方服务监控指标并暴露metrics
-
Alertmanager:告警
-
Web UI:简单的Web控制台
Prometheus基本使用:部署
部署Prometheus:
docker run -d --name=prometheus -p 9090:9090 prom/prometheus |
访问地址:http://ip:9090/
部署文档:https://prometheus.io/docs/prometheus/latest/installation/
部署Grafana:
docker run -d --name=grafana -p 3000:3000 grafana/grafana |
访问地址:http://ip:3000/
部署文档:https://grafana.com/grafana/download
用户名/密码:admin/admin # 第一次需要重置密码

Prometheus基本使用:监控Linux服务器
node_exporter:用于监控Linux系统的指标采集器。
常用指标:
-
CPU
-
内存
-
硬盘
-
网络流量
-
文件描述符
-
系统负载
-
系统服务
数据接口:http://ip:9100/
使用文档:https://prometheus.io/docs/guides/node-exporter/
GitHub:https://github.com/prometheus/node_exporter
在Prometheus配置文件添加被监控端:
scrape_configs: |
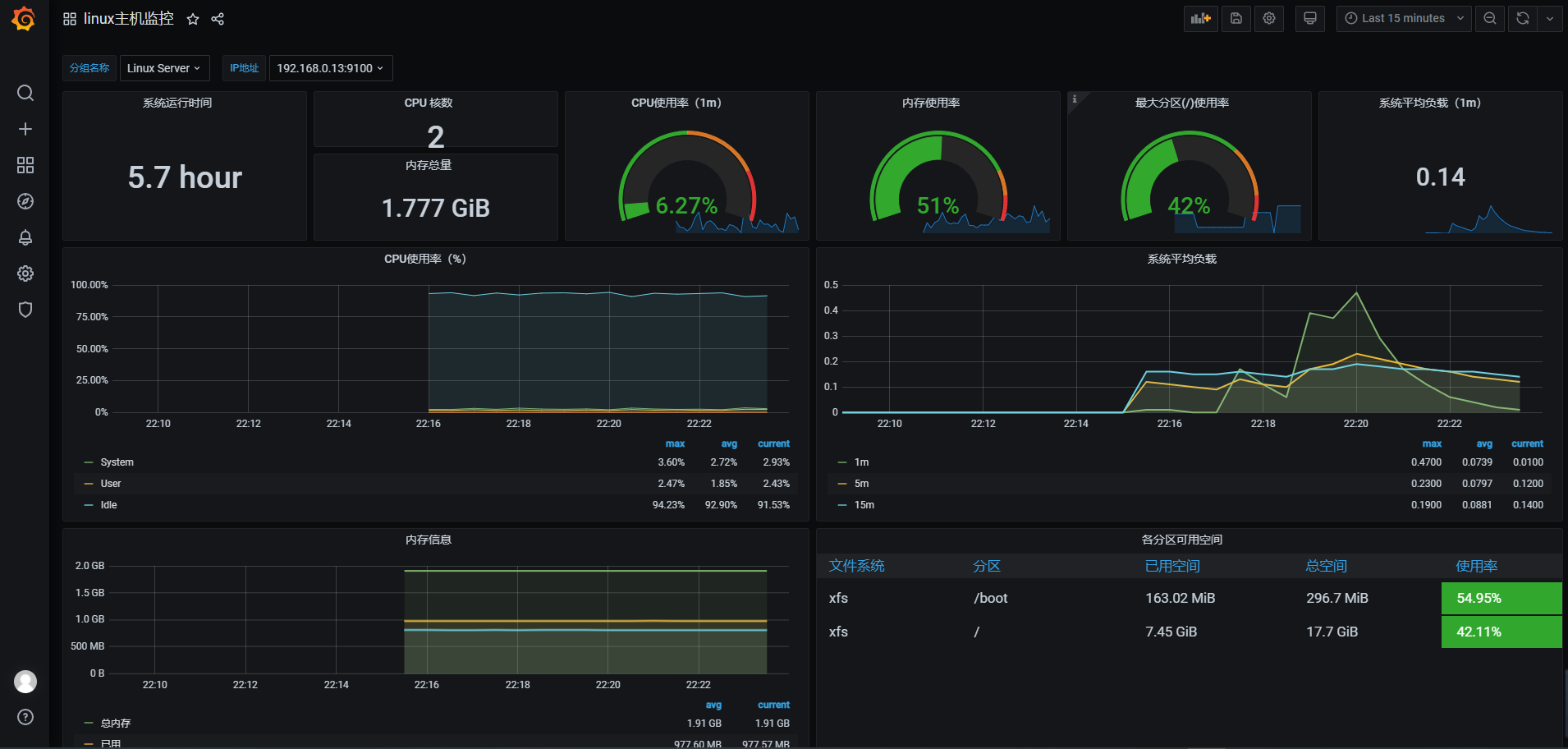
使用Grafana展示node_exporter数据指标,仪表盘ID: 9276
Prometheus基本使用:查询数据
PromQL(Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰 富,支持条件查询、操作符,并且内建了大量内置函数,供我们针对监控数据的各种维度进行查询。
数据模型:
-
Prometheus将所有数据存储为时间序列;
-
具有相同度量名称以及标签属于同一个指标;
-
每个时间序列都由度量标准名称和一组键值对(称为标签)唯一标识, 通过标签查询指定指标。
指标格式:
示例:
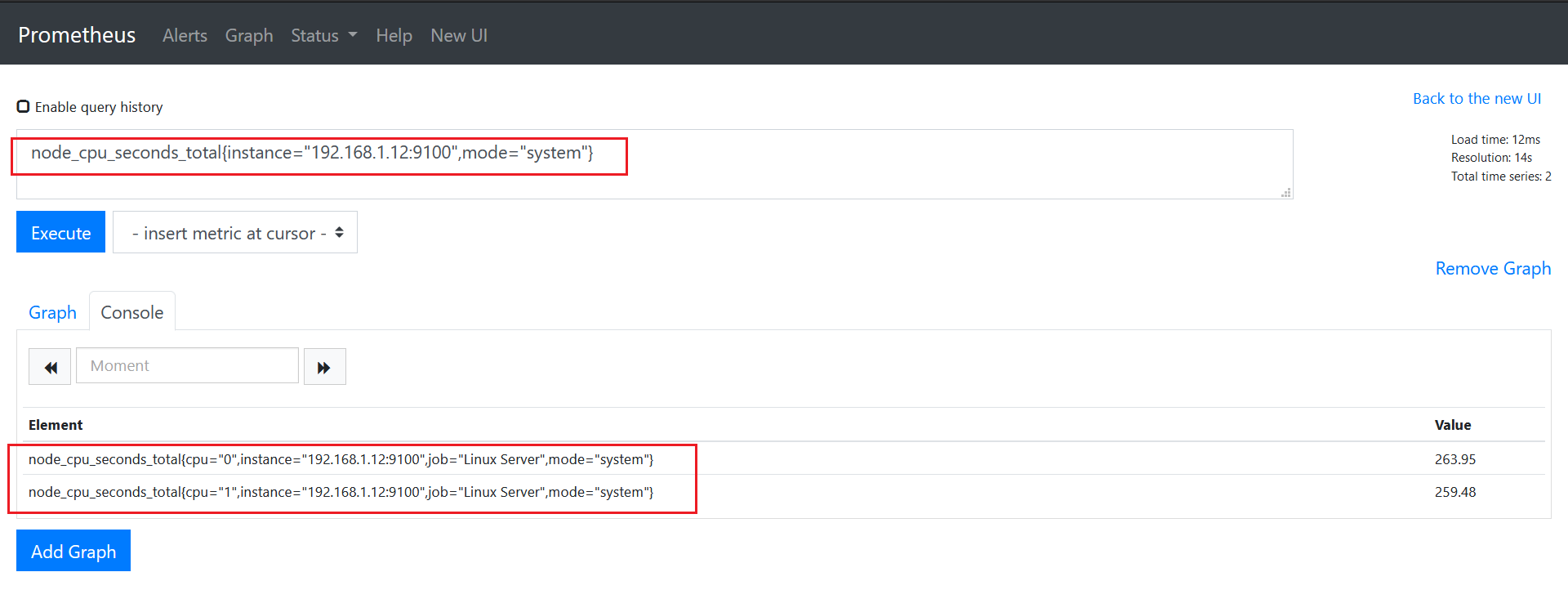
查询指标最新样本(称为瞬时向量):
node_cpu_seconds_total
可以通过附加一组标签来进一步过来这些时间序列:
node_cpu_seconds_total{job=“Linux Server”}
查询指标近5分钟内样本(称为范围向量,时间单位 s,m,h,d,w,y): node_cpu_seconds_total{job=“Linux Server”}[5m]
node_cpu_seconds_total{job=“Linux Server”}[1h]
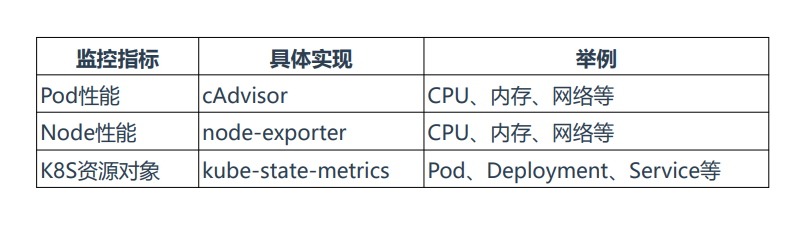
Kubernetes 监控指标
Kubernetes本身监控
-
Node资源利用率
-
Node数量
-
每个Node运行Pod数量
-
资源对象状态
Pod监控
-
Pod总数量及每个控制器预期数量
-
Pod状态
-
容器资源利用率:CPU、内存、网络
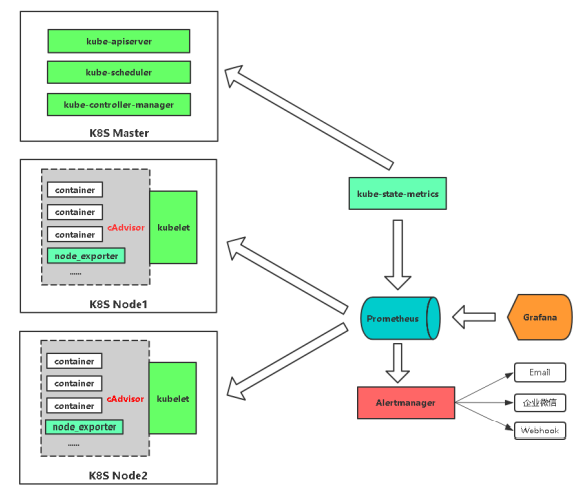
Kubernetes 监控实现思路
Pod
kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有Pod和容器相关的性能指标数据。
指标接口:https://NodeIP:10250/metrics/cadvisor
Node
使用node_exporter收集器采集节点资源利用率。
项目地址:https://github.com/prometheus/node_exporter
K8s资源对象
kube-state-metrics采集了k8s中各种资源对象的状态信息。
项目地址:https://github.com/kubernetes/kube-state-metrics
在Kubernetes平台部署相关组件
-
prometheus-deployment.yaml # 部署Prometheus
-
prometheus-configmap.yaml # Prometheus配置文件,主要配置Kubernetes服务发现
-
prometheus-rules.yaml # Prometheus告警规则
-
grafana.yaml # 可视化展示
-
node-exporter.yml # 采集节点资源,通过DaemonSet方式部署,并声明让Prometheus收集
-
kube-state-metrics.yaml # 采集K8s资源,并声明让Prometheus收集
-
alertmanager-configmap.yaml # 配置文件,配置发件人和收件人
-
alertmanager-deployment.yaml # 部署Alertmanager告警组件
#安装nfs安装包(每个k8s节点都要安装) |
kubernetes-node-kubelet:获取kebelet暴露的指标,访问地址https://NodeIP:10250/metrics |
#prometheus和altermanger手动热加载配置 |
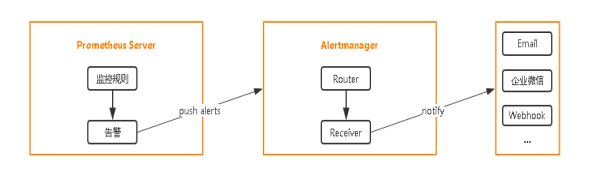
Prometheus 告警
Prometheus报警功能利用Alertmanager组件完成,当Prometheus会对接收的指标数据比对告警规则,如果 满足条件,则将告警事件发送给Alertmanager组件,Alertmanager组件发送到接收人。
使用步骤:
-
部署Alertmanager
-
配置告警接收人
-
配置Prometheus与Alertmanager通信
-
在Prometheus中创建告警规则
global: |
# vi prometheus.yml |
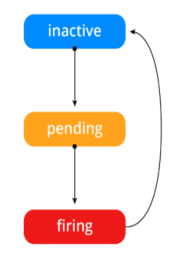
告警状态:
-
Inactive:这里什么都没有发生。
-
Pending:已触发阈值,但未满足告警持续时间
-
Firing:已触发阈值且满足告警持续时间。警报发送给接受者。
小结:
1.在k8s中部署应用,在service或者pod中配置注解
annotations:
prometheus.io/scrape: 'true'
2.数据被采集到,可以写任意告警规则,出现问题,第一时间通知你
3.如果grafana仪表盘无法满足需求,可以自定义
4.grafana图标没数据,数据没采集到,promq写的有问题,服务器时间没同步
5.altermanger和prometheus配置文件如果没生效,手动配置热加载
curl -XPOST 10.244.169.152:9093/-/reload
curl -XPOST 10.244.26.74:9090/-/reload