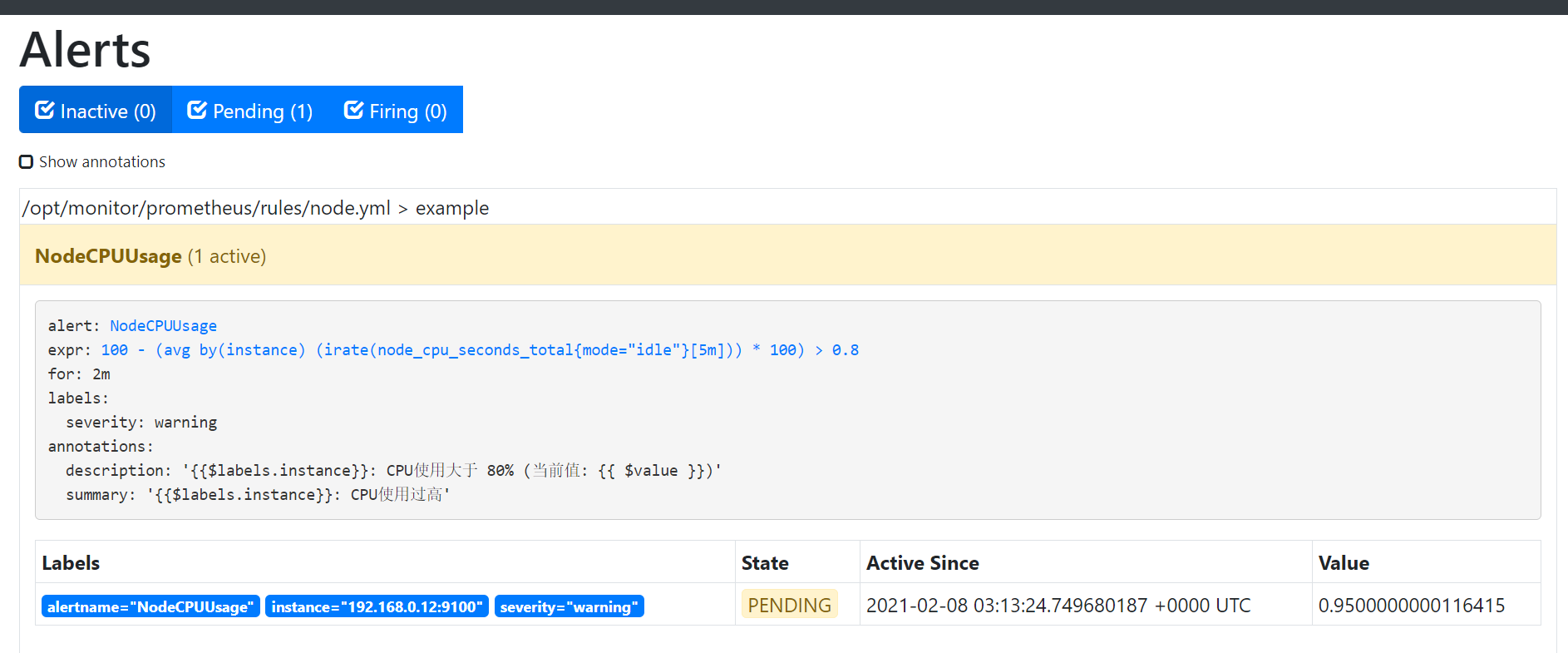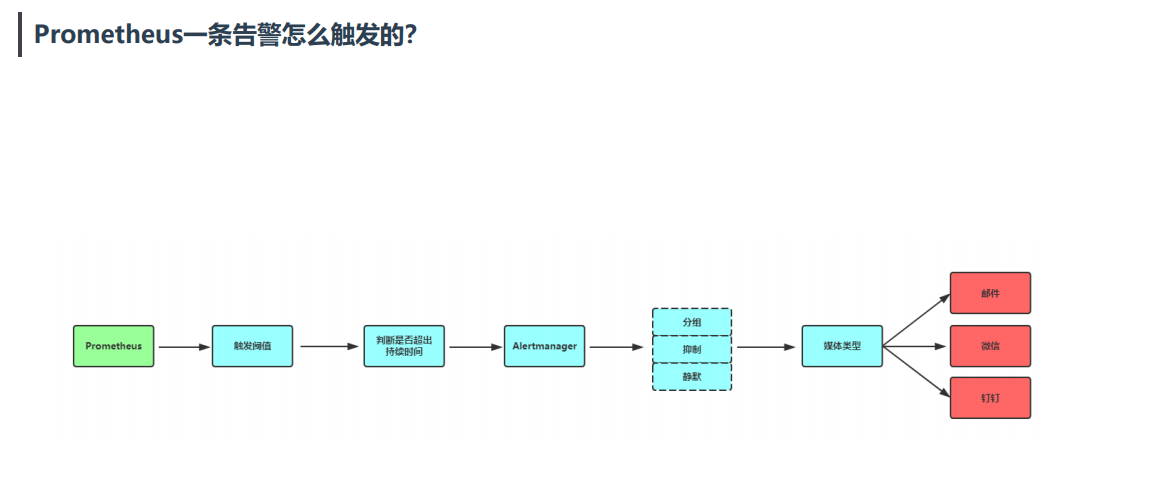
在prometheus配置里面创建告警规则
判断当前实例的状态是否正常,up=1代表正常,up=0代表失联,不正常
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 2m
labels:
severity: error
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }}: job {{ $labels.job }} 已经停止5分钟以上."
|
统计cpu,内存,文件系统的使用率,超过80%发送告警
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用过高"
description: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用大于 80% (当前值: {{ $value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 内存使用过高"
description: "{{$labels.instance}}: 内存使用大于 80% (当前值: {{ $value }})"
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: CPU使用过高"
description: "{{$labels.instance}}: CPU使用大于 80% (当前值: {{ $value }})"
|
进入for评估周期中