安装包下载
地址1:https://prometheus.io/download/
地址2:https://github.com/prometheus/alertmanager/releases
使用步骤:
-
部署Alertmanager
-
配置告警接收人
-
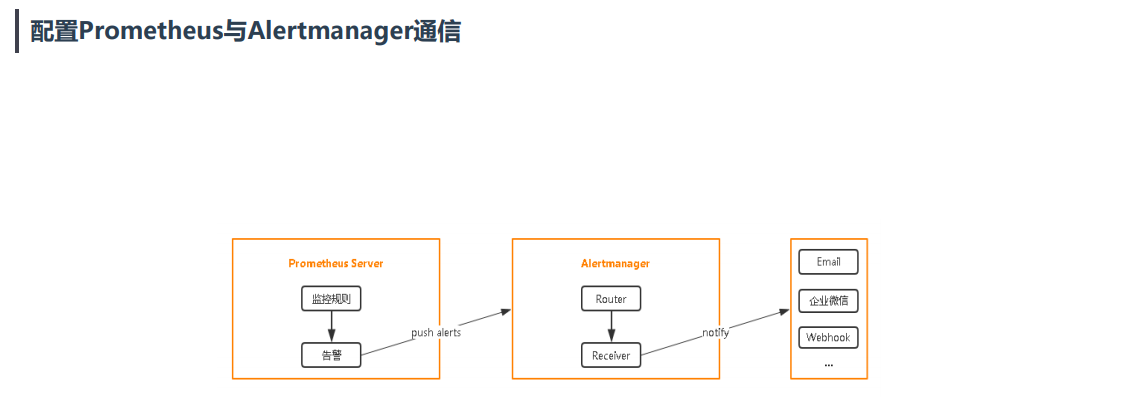
配置Prometheus与Alertmanager通信
-
在Prometheus中创建告警规则
部署Alertmanager (端口9093)
tar -zxf alertmanager-0.21.0.linux-amd64.tar.gz
mv alertmanager-0.21.0.linux-amd64 /opt/monitor/alertmanager
vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
[Service]
ExecStart=/opt/monitor/alertmanager/alertmanager --config.file=/opt/monitor/alertmanager/alertmanager.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start alertmanager
systemctl enable alertmanager
|
配置Prometheus与Alertmanager通信并配置告警接收人

alertmanager工作目录下配置
vim /opt/monitor/alertmanager/alertmanager.yml
|
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.sina.com:25'
smtp_from: 'lz13753705474@sina.com'
smtp_auth_username: 'lz13753705474@sina.com'
smtp_auth_password: '0b06987008049d86'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: '1437626743@qq.com'
|
配置完成后,重启服务
systemctl start alertmanager
|
在Prometheus中创建告警规则
vim /opt/monitor/prometheus/prometheus.yml
|
启用告警配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
|
这个目录就是一个相对路径
rule_files:
- "rules/*.yml"
|
创建告警规则目录rules以及创建告警规则文件node.yml
mkdir /opt/monitor/prometheus/rules
cd /opt/monitor/prometheus/rules
vim node.yml
|
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: page
annotations:
summary: " {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }}:job {{ $labels.job }} 已经停止5分钟以
上."
|
配置完成后,重新加载服务
kill -HUP <prometheus pid>
|
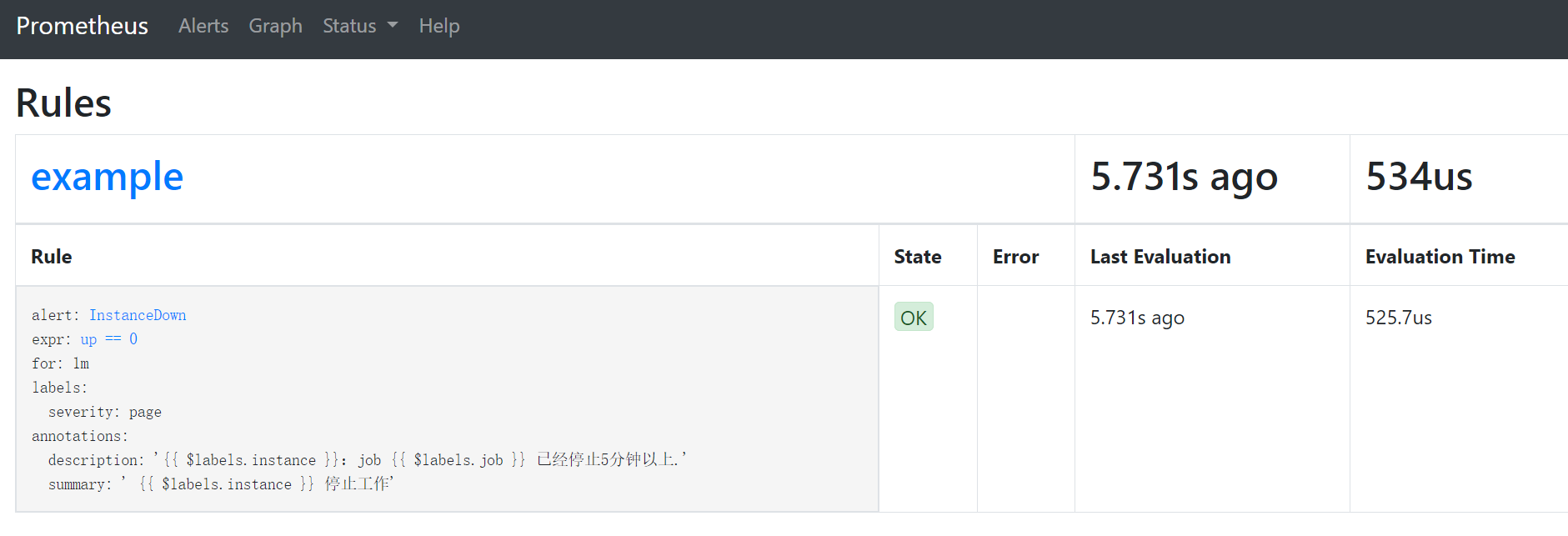
查看告警规则是否生效
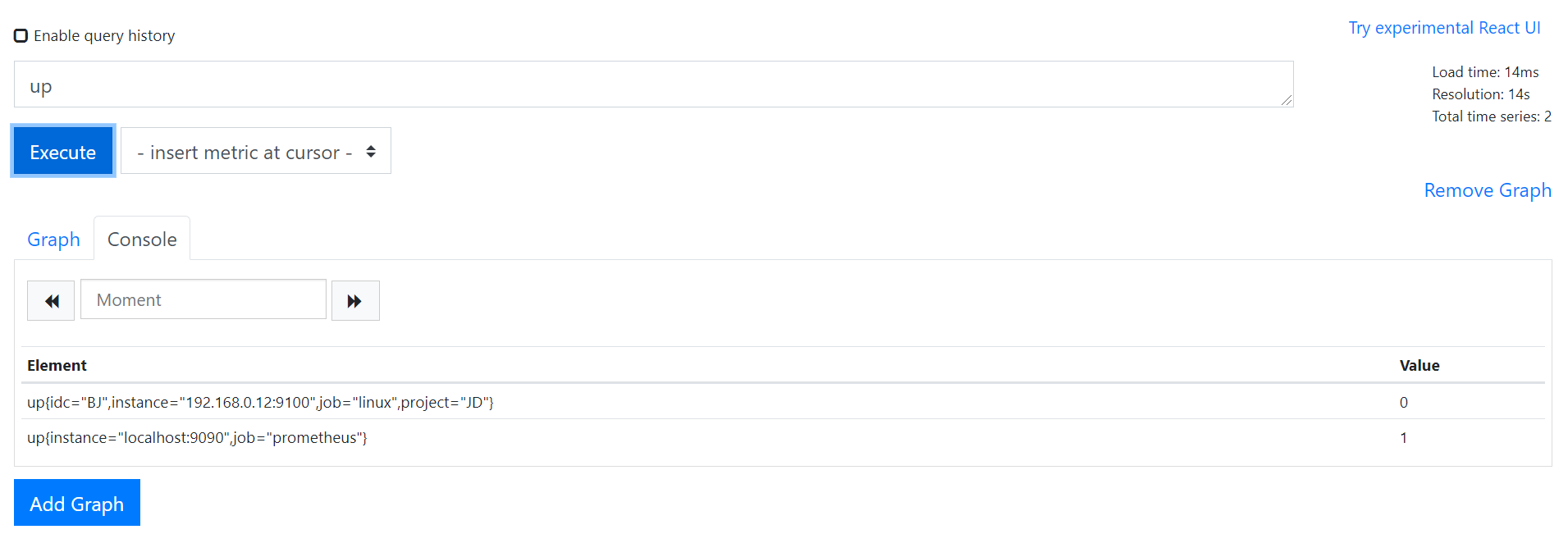
每个被监控端都有up这个标签,up为1代表服务正常,如果等于0代表服务不正常。所以可以通过up获取所有的被监控端状态
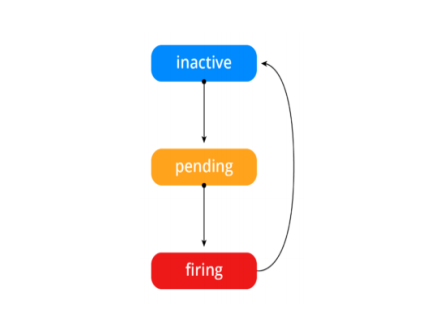
告警状态
• Inactive:这里什么都没有发生。
• Pending:已触发阈值,但未满足告警持续时间
• Firing:已触发阈值且满足告警持续时间。警报发送给接受者。
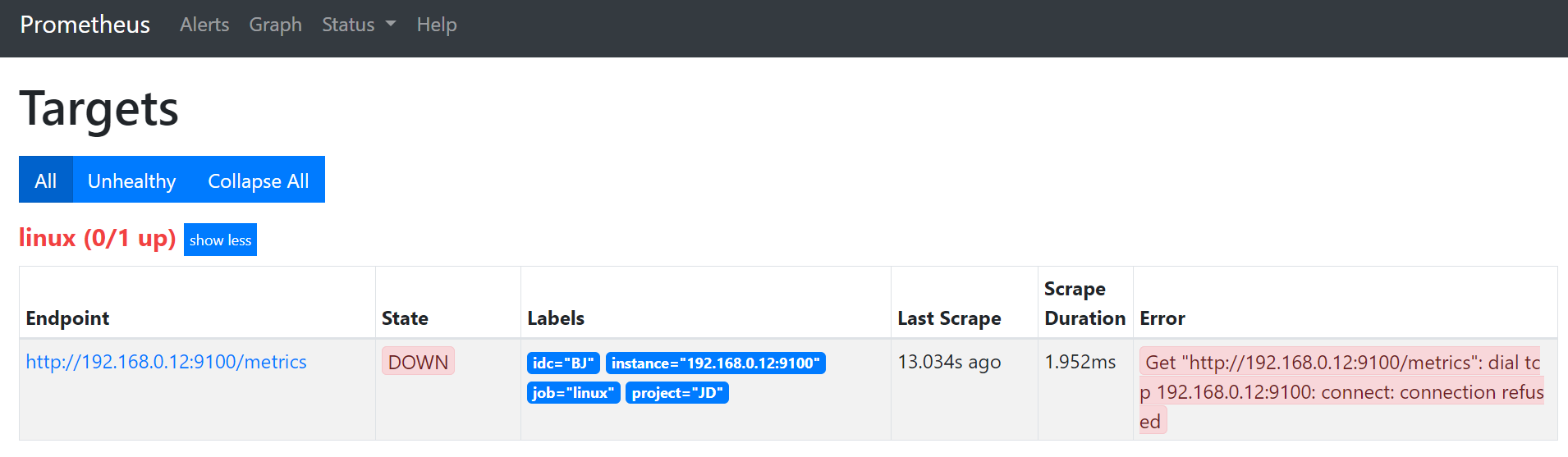
现在模拟关闭一台被监控端的node_exporter服务
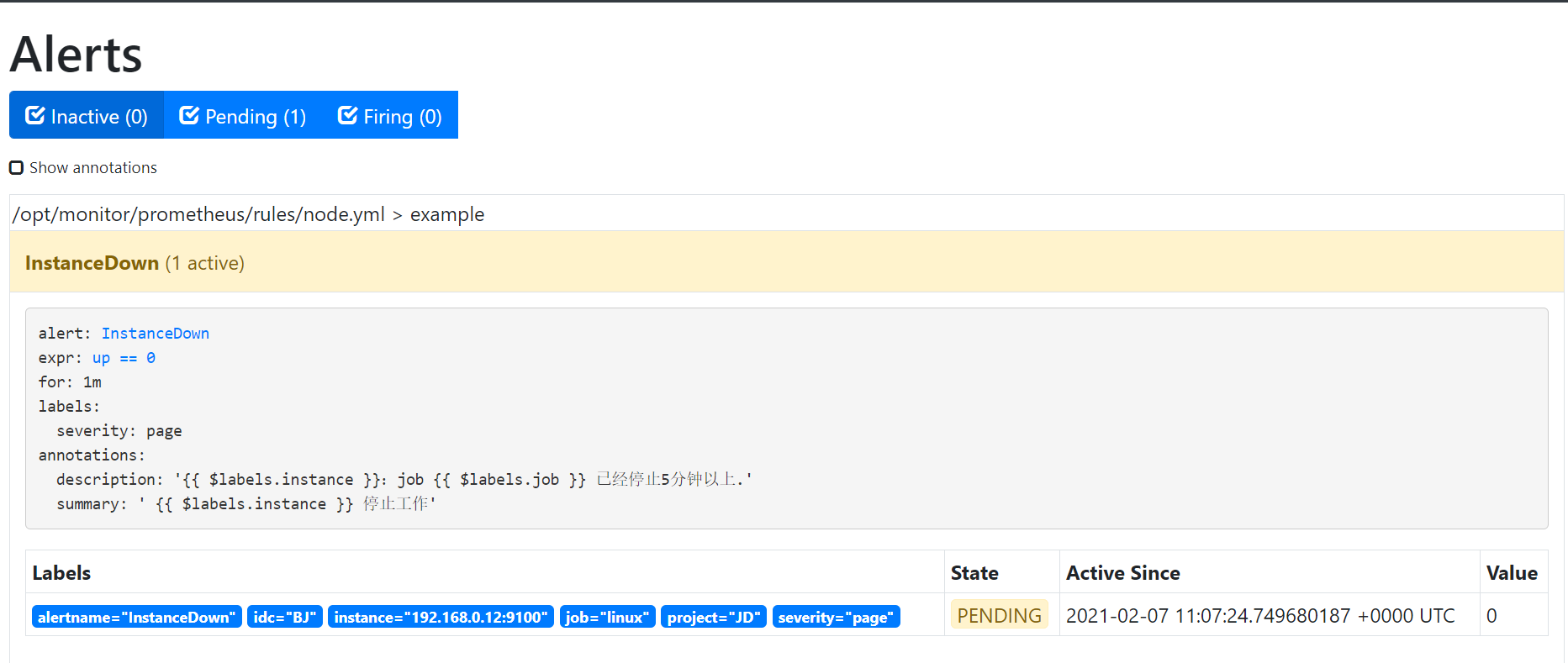
被监控端一个主机down了,查看告警 ,可以看到告警处于pending的状态,进入for循环评估当中
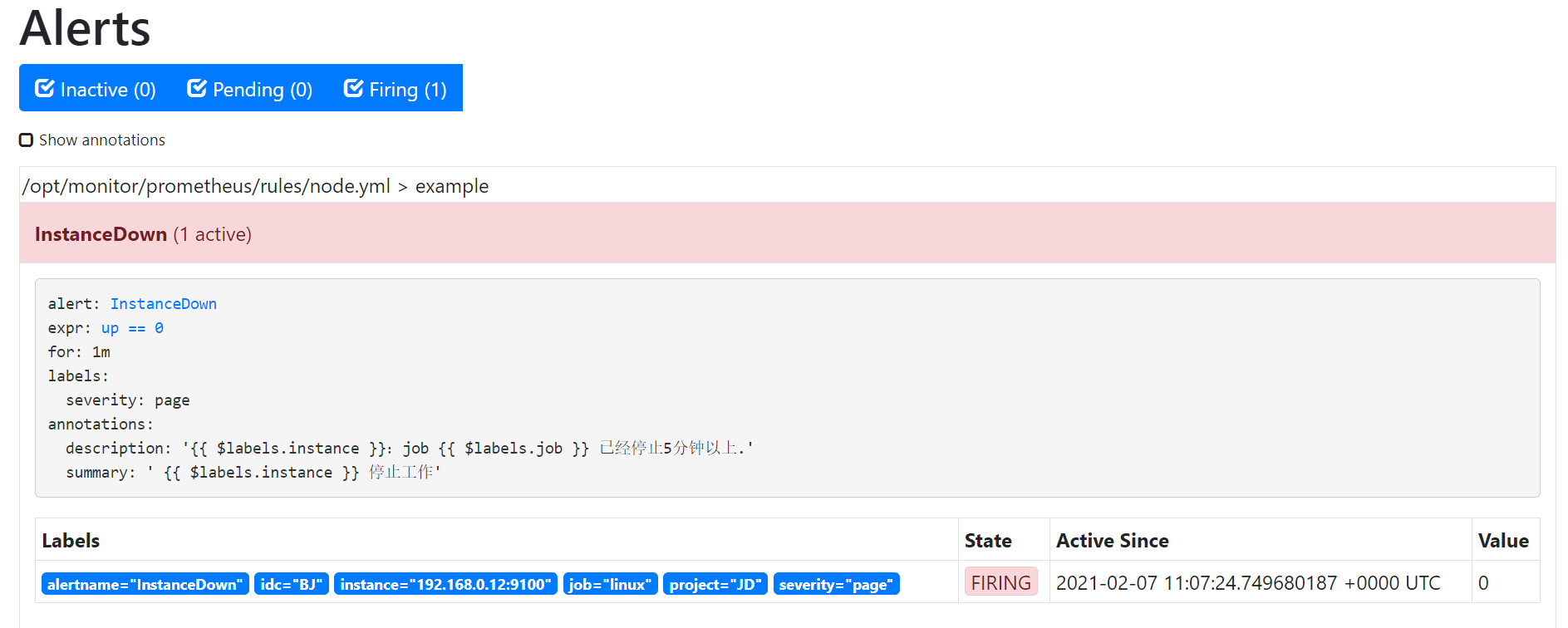
在评估期内满足条件告警状态触发了,此时状态为Firing
这里可以在告警规则里面定义一些标签,方便后期的处理,主要是在altermanager里面体现
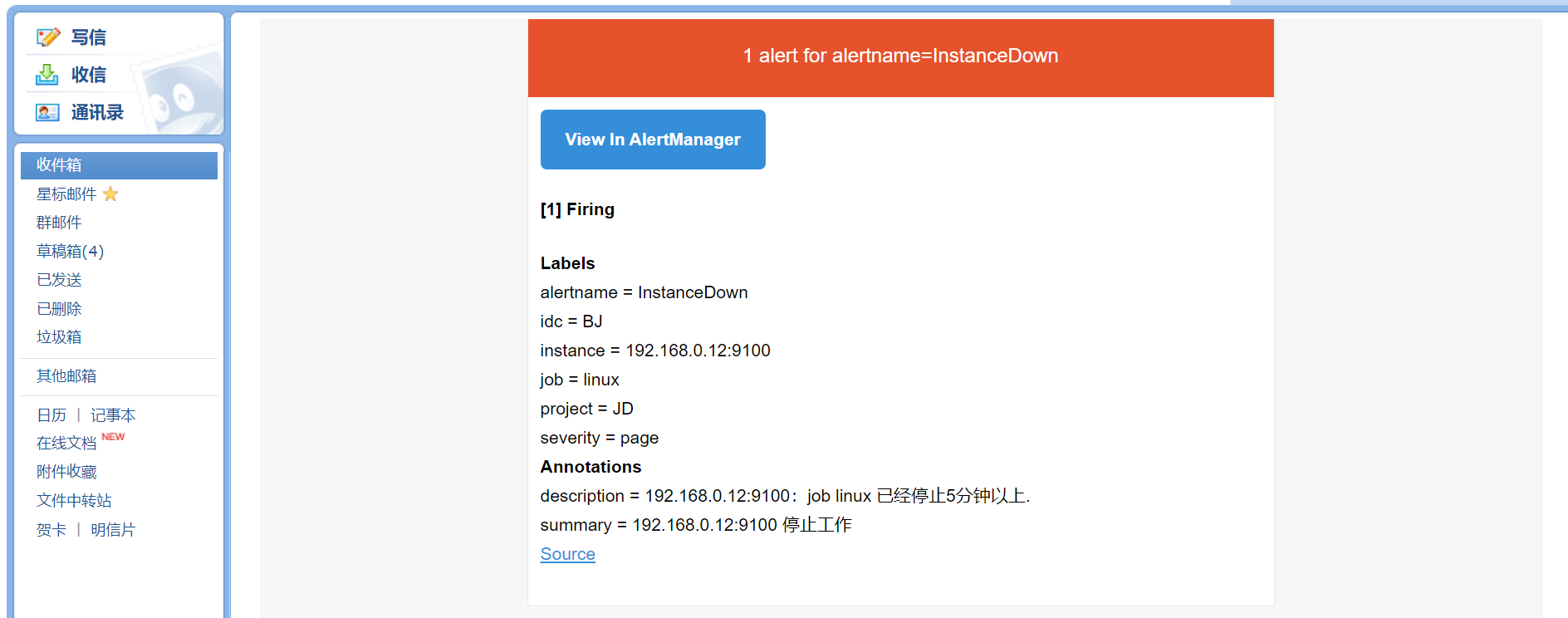
最后邮件查看