过滤插件:Grok
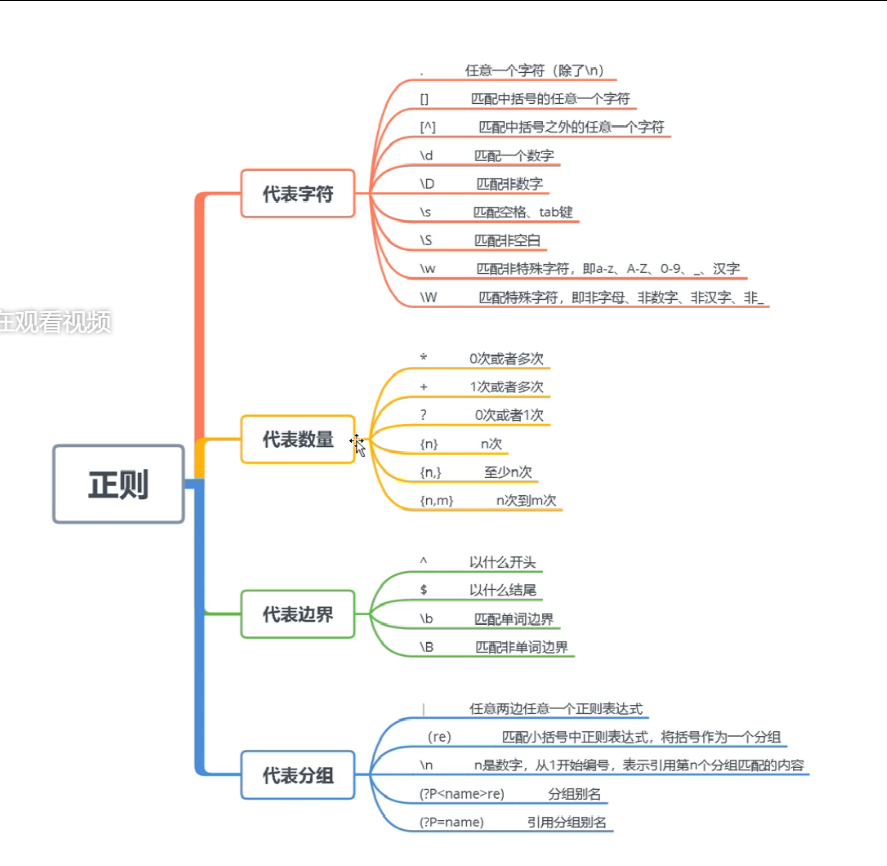
Grok插件:如果采集的日志格式是非结构化的,可以写正则表 达式提取,grok是正则表达式支持的实现。
常用字段:
• match 正则匹配模式
• patterns_dir 自定义正则模式文件
Logstash内置的正则匹配模式,在安装目录下可以看到,路径: vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
正则匹配模式语法格式:%{SYNTAX:SEMANTIC}
• SYNTAX 模式名称,模式文件中的第一列
• SEMANTIC 匹配文件的字段名
例如: %{IP:client}
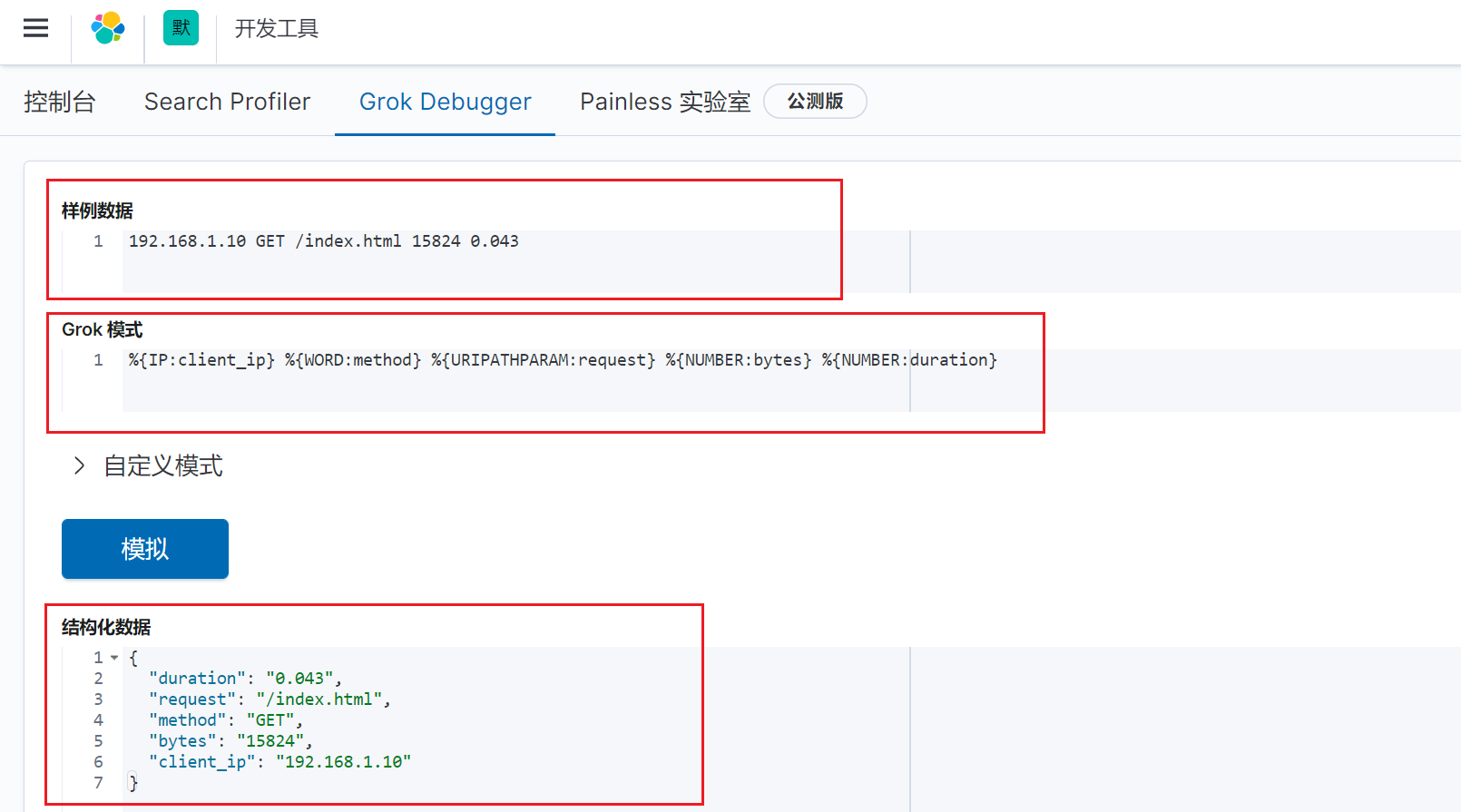
示例:正则匹配HTTP请求日志
修改logstash配置文件
vim /opt/elk/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test/*.log"
exclude => "1.log"
start_position => "beginning"
tags => "web"
tags => "nginx"
type => "access"
add_field => {
"project" => "microservice"
"app" => "product"
}
}
}
filter {
grok {
match => {
"message" => "%{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
output {
elasticsearch {
hosts =>
["192.168.0.11:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
|
热加载配置
模拟数据
echo "192.168.1.12 GET /log.html 192822 0.053" >>/var/log/test/2.log
|
在kibana上验证:
未使用grok正则格式化前的kibana展示页面
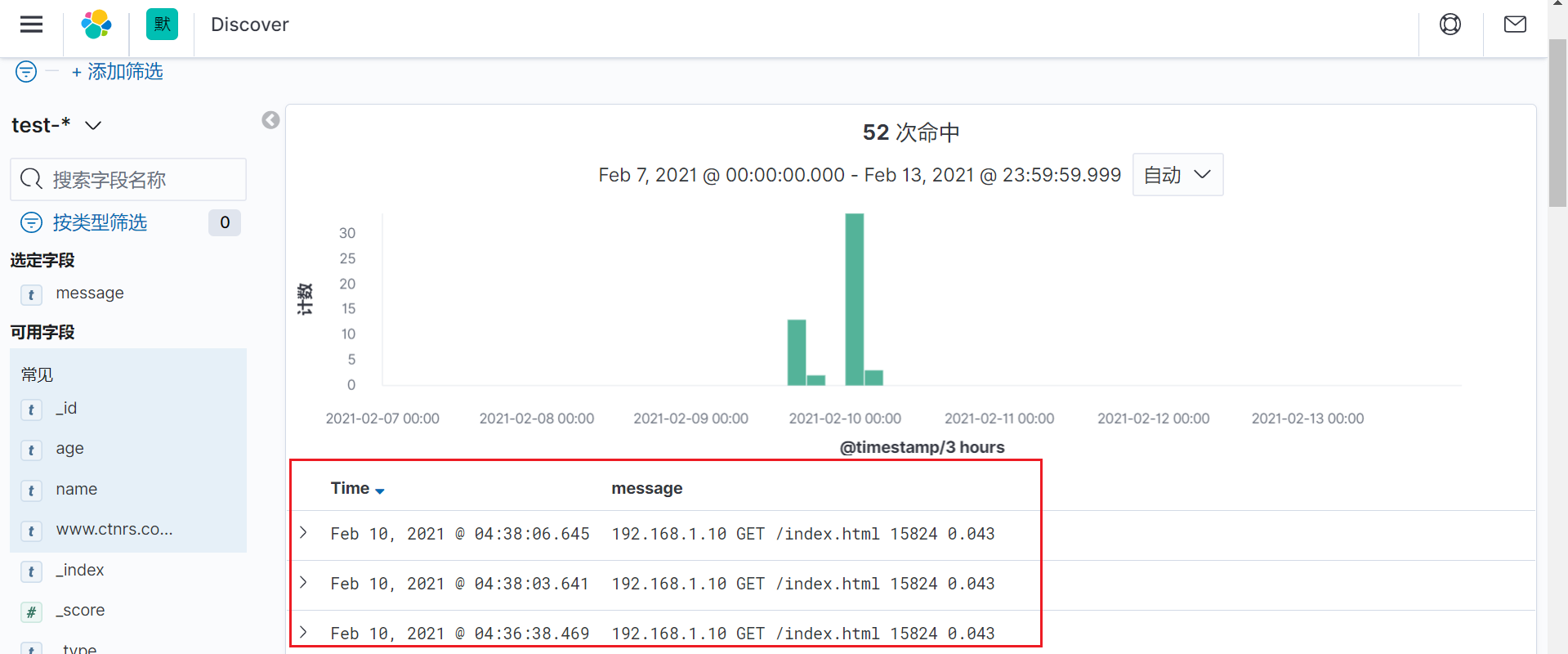
使用grok正则格式化后的kibana展示页面
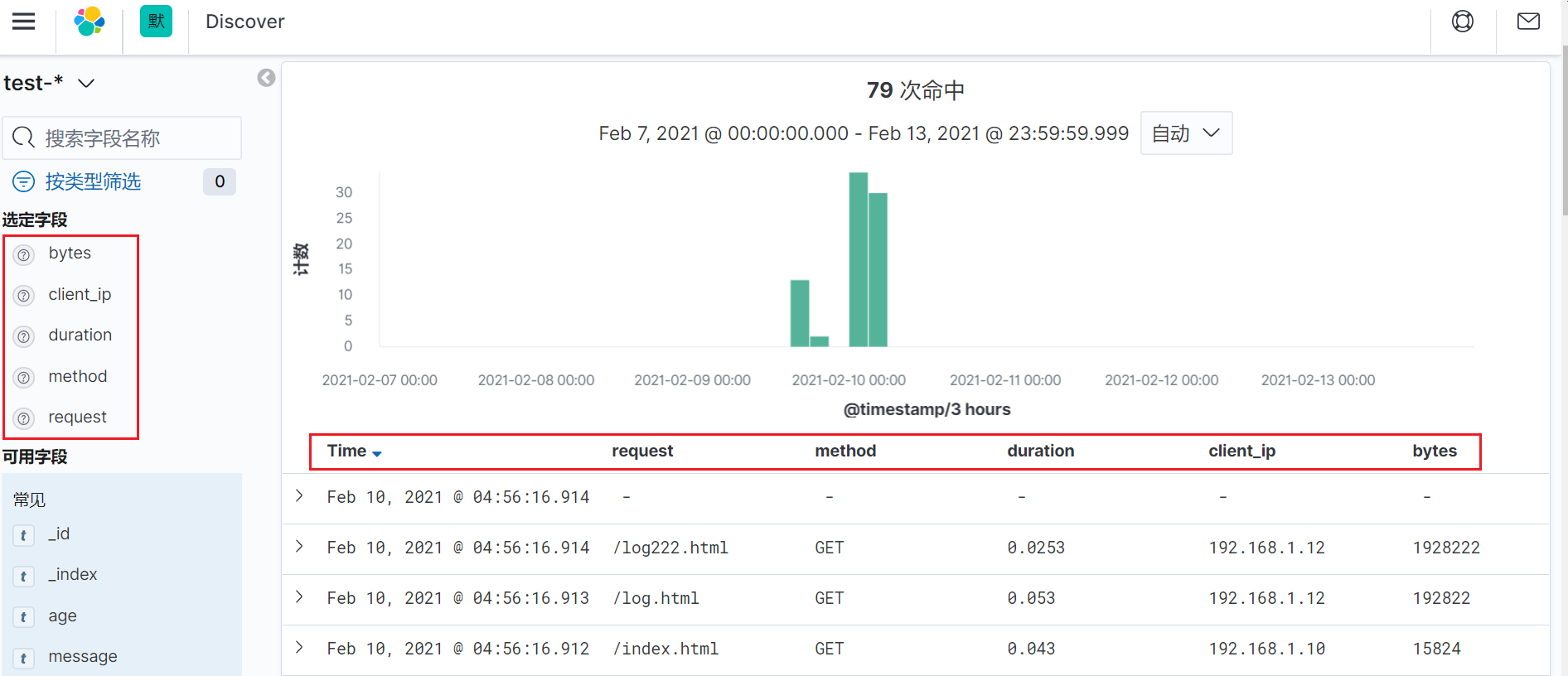
从上面可以看到,使用grok正则格式化数据后,会增加了几个字段,这个字段就是我们使用正则添加的几个字段,它是从message字段中提取的值,然后将这些值赋予了新的字段。这样的好处是,我们可以基于某个字段去查询数据,比如我们可以分析持续时间大于1秒的日志等待。
如果内置匹配模式中没有你想要的,可以自定义正则模式。
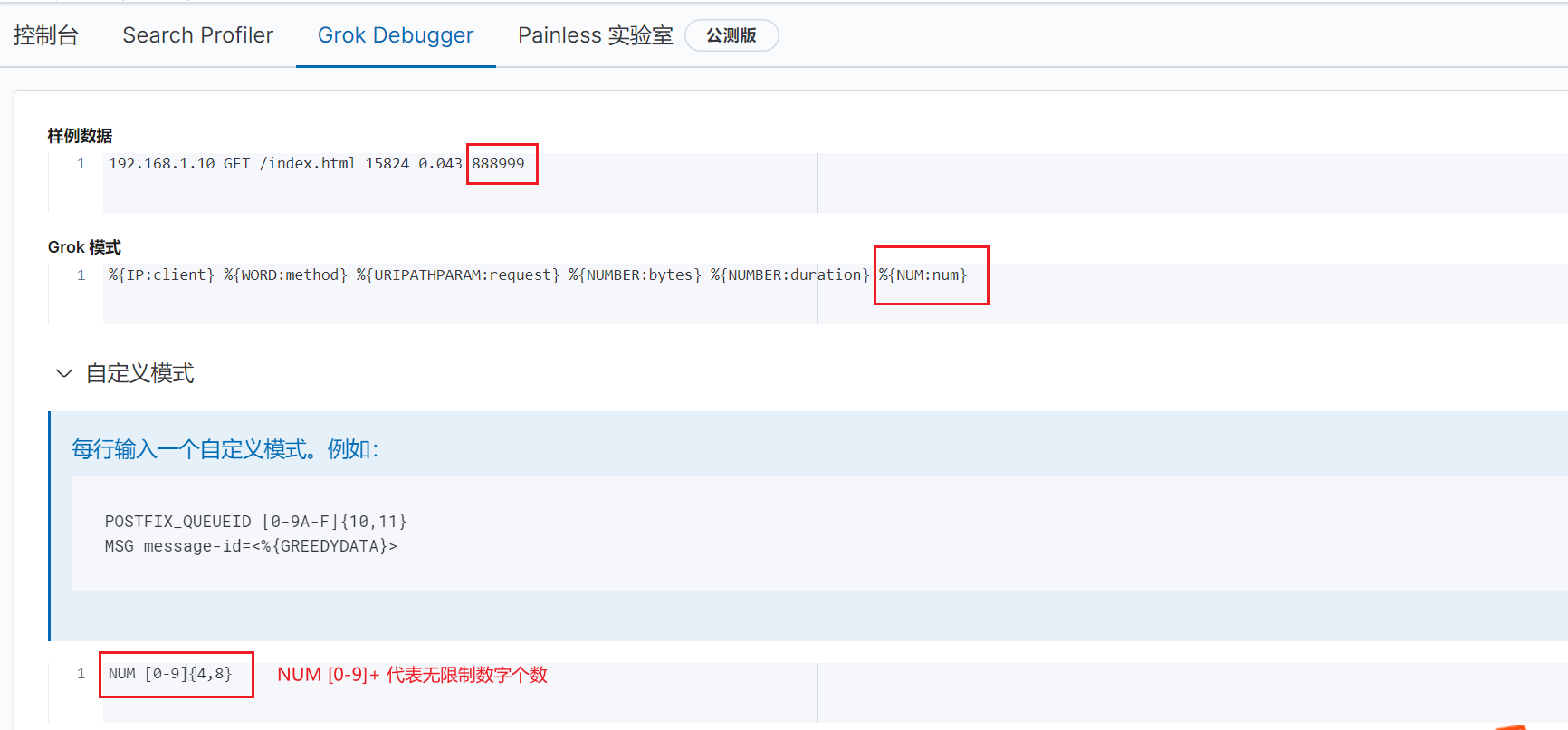
创建自定义正则模式文件
vim /opt/patterns
NUM [0-9]{4,8}
|
修改logstash配置文件
vim /opt/elk/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test/*.log"
exclude => "1.log"
start_position => "beginning"
tags => "web"
tags => "nginx"
type => "access"
add_field => {
"project" => "microservice"
"app" => "product"
}
}
}
filter {
grok {
patterns_dir => "/opt/patterns"
match => {
"message" => "%{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{NUM:num}"
}
}
}
output {
elasticsearch {
hosts =>
["192.168.0.11:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
|
热加载配置
模拟数据
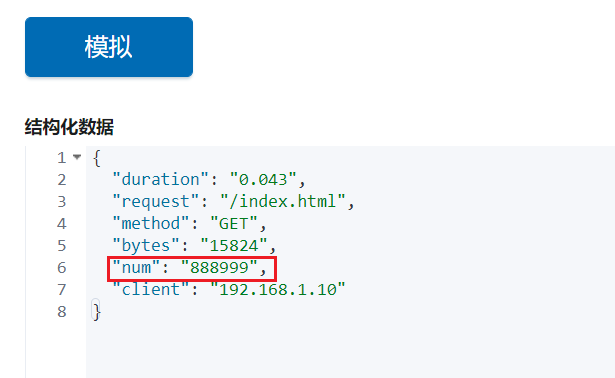
vim /var/log/test/2.log
192.168.1.15 GET /task.html 15824 0.043 888999
|
在kibana页面上查看
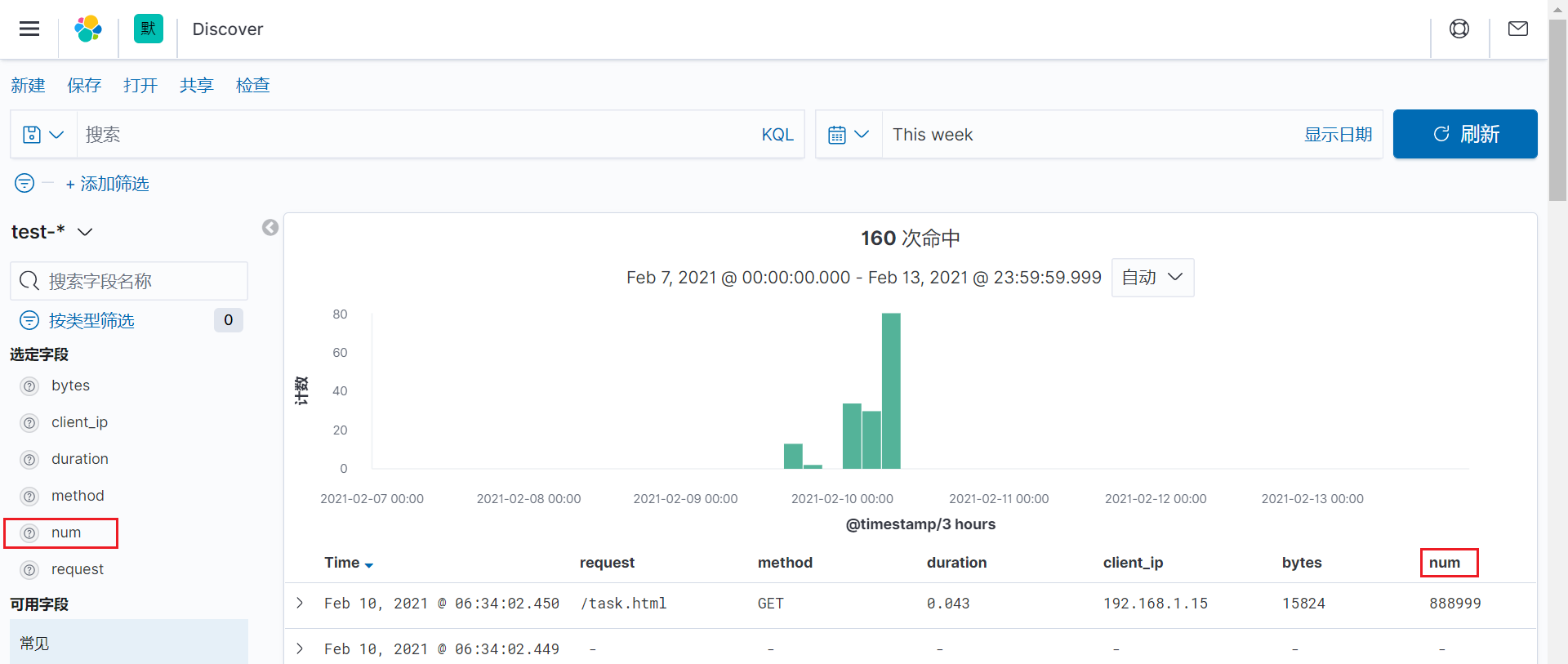
从上面可以看到,通过自定义正则的模式,我们可以制定出我们想要的正则模式。
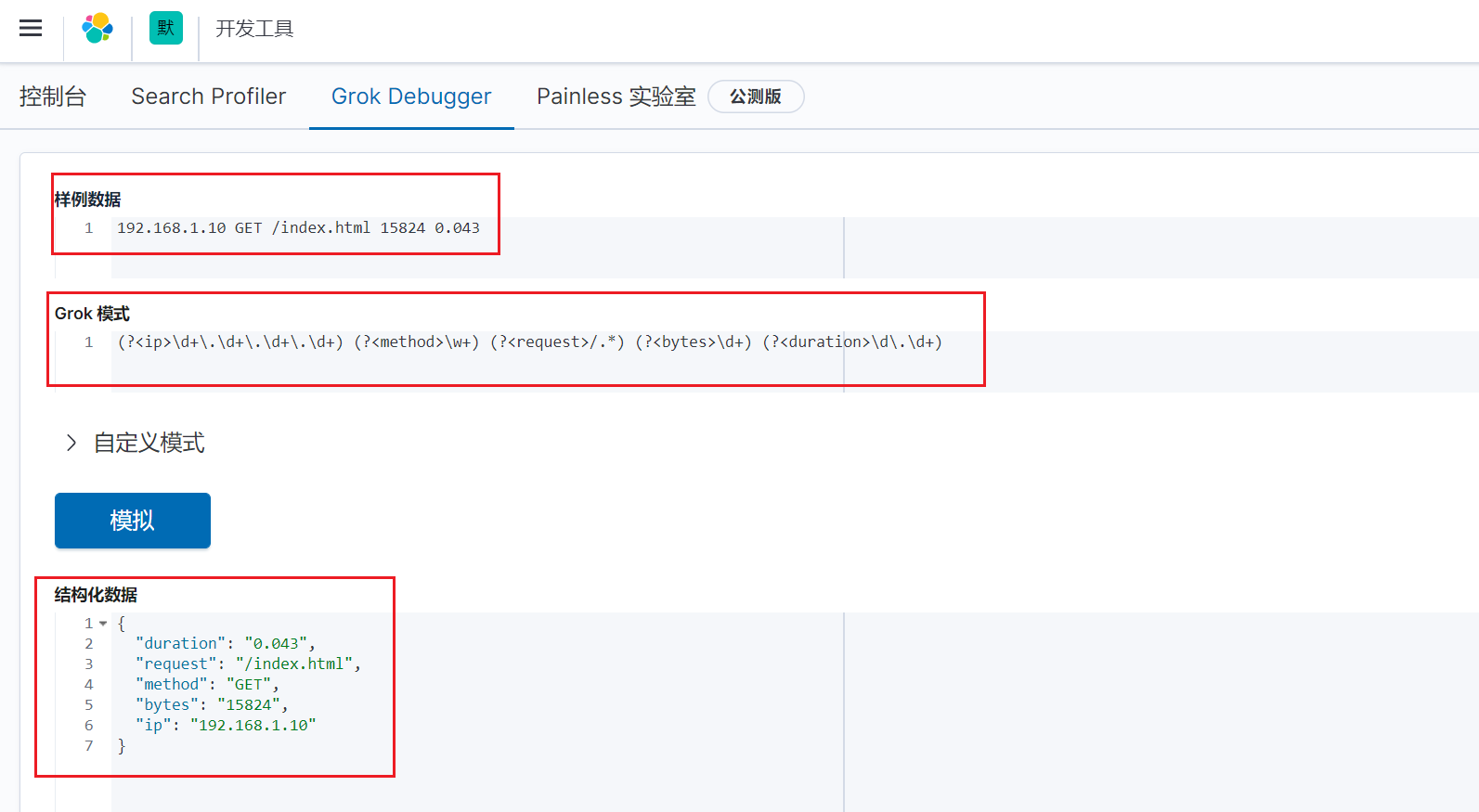
我们可以使用其他的正则,不一定使用内置的正则,这样更灵活一点。
如果一个日志文件下有多个日志格式怎么办?例如项目新版本添加一个日志字段,需要兼容旧日志匹配 使用多模式匹配,写多个正则表达式,只要满足其中一条就能匹配成功。
创建自定义正则模式文件
vim /opt/patterns
NUM [0-9]{4,8}
MUM [a-z]{4,8}
TAG \w+
|
修改配置文件
vim /opt/elk/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test/*.log"
exclude => "1.log"
start_position => "beginning"
tags => "web"
tags => "nginx"
type => "access"
add_field => {
"project" => "microservice"
"app" => "product"
}
}
}
filter {
grok {
patterns_dir => "/opt/patterns"
match => [
"message", "%{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{NUM:num}",
"message", "%{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{MUM:mum} %{TAG:tag}"
]
}
}
output {
elasticsearch {
hosts =>
["192.168.0.11:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
|
加载配置
模拟数据
vim /var/log/test/2.log
192.168.1.15 GET /task.html 15824 0.043 ssssssss azhe123
192.168.1.15 GET /task.html 15824 0.043 10010
|
在kibana页面上查看
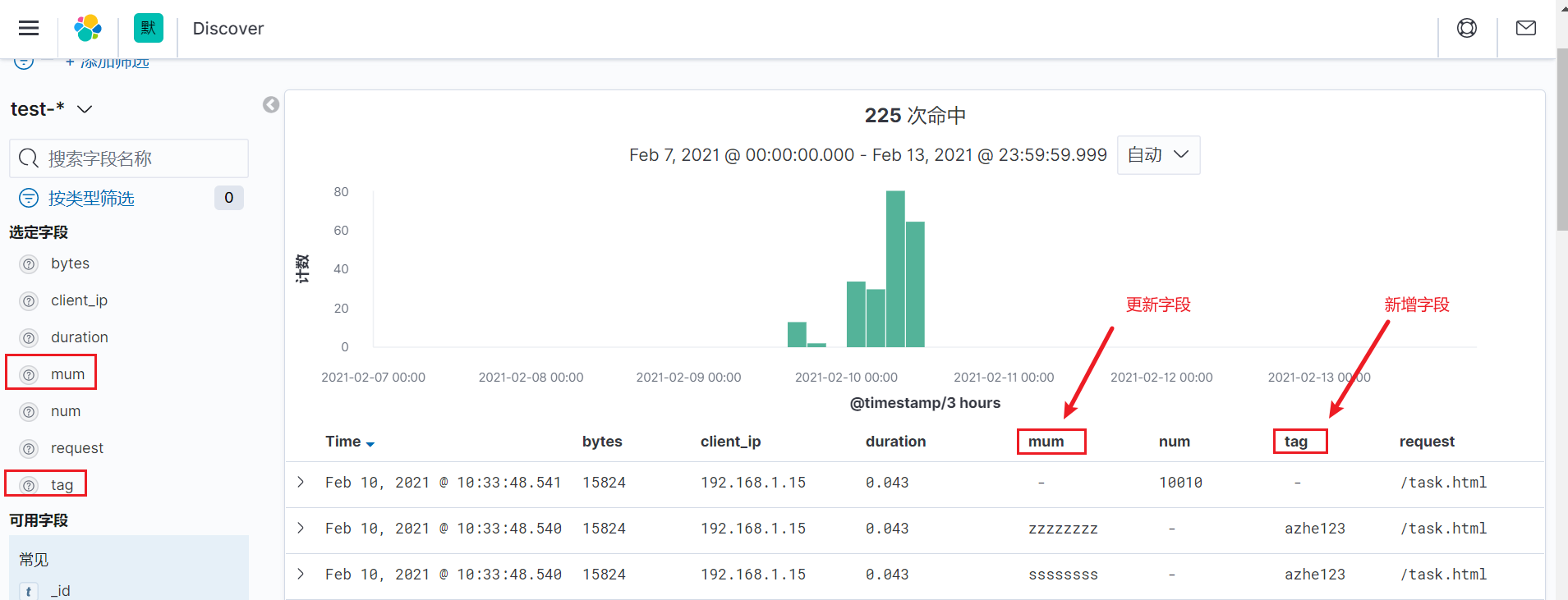
从上面可以看出,我们可以多模式匹配日志,新版本和旧版本日志共存。
过滤插件:GeoIP
GeoIP插件:根据Maxmind GeoLite2数据库中的数据添加有关IP地址位置信息。 使用多模式匹配,写多个正则表达式,只要满足其中一条就能匹配成功。
常用字段:
• source 指定要解析的IP字段,结果保存到geoip字段
• database GeoLite2数据库文件的路径
• fields 保留解析的指定字段
下载地址: https://www.maxmind.com/en/accounts/436070/geoip/downloads(需要登录)
tar -zxf GeoLite2-City_20201103.tar.gz
mv GeoLite2-City_20201103/GeoLite2-City.mmdb /opt/
|
修改logstash配置文件
vim /opt/elk/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test/*.log"
exclude => "1.log"
start_position => "beginning"
tags => "web"
tags => "nginx"
type => "access"
add_field => {
"project" => "microservice"
"app" => "product"
}
}
}
filter {
grok {
patterns_dir => "/opt/patterns"
match => [
"message", "%{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{NUM:num}",
"message", "%{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{MUM:mum} %{TAG:tag}"
]
}
geoip {
source => "client_ip"
database => "/opt/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts =>
["192.168.0.11:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
|
热加载配置
在kibana页面上查看
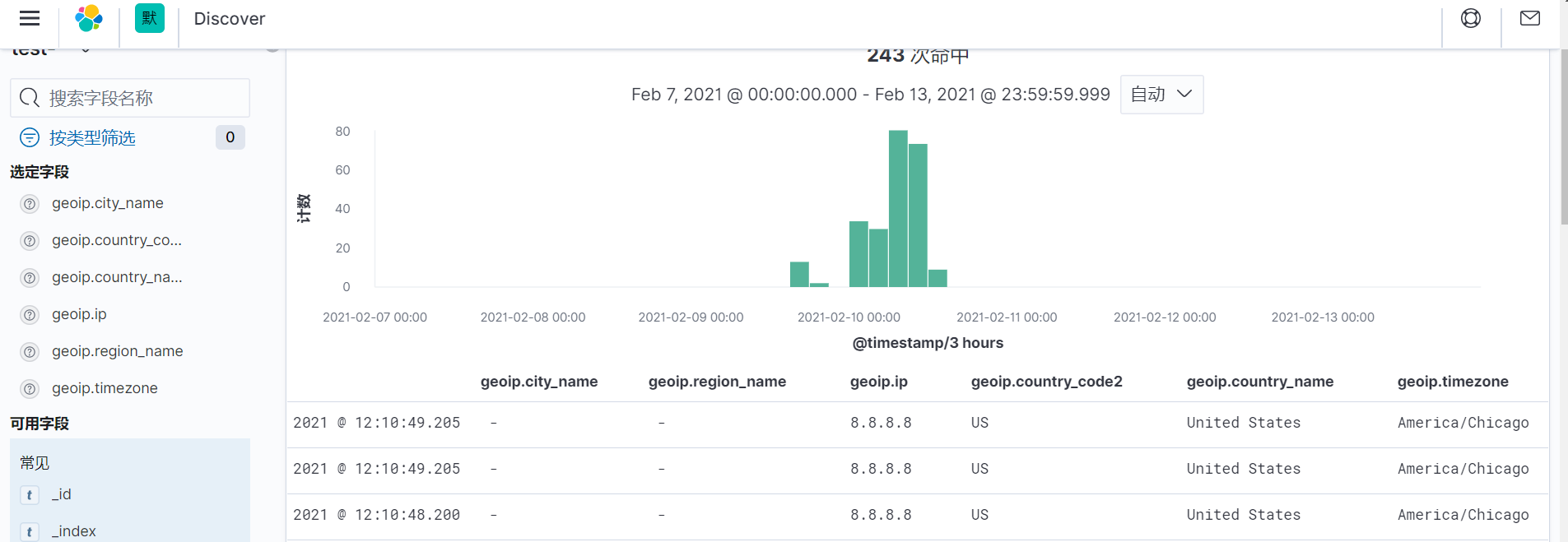
过滤插件:Date
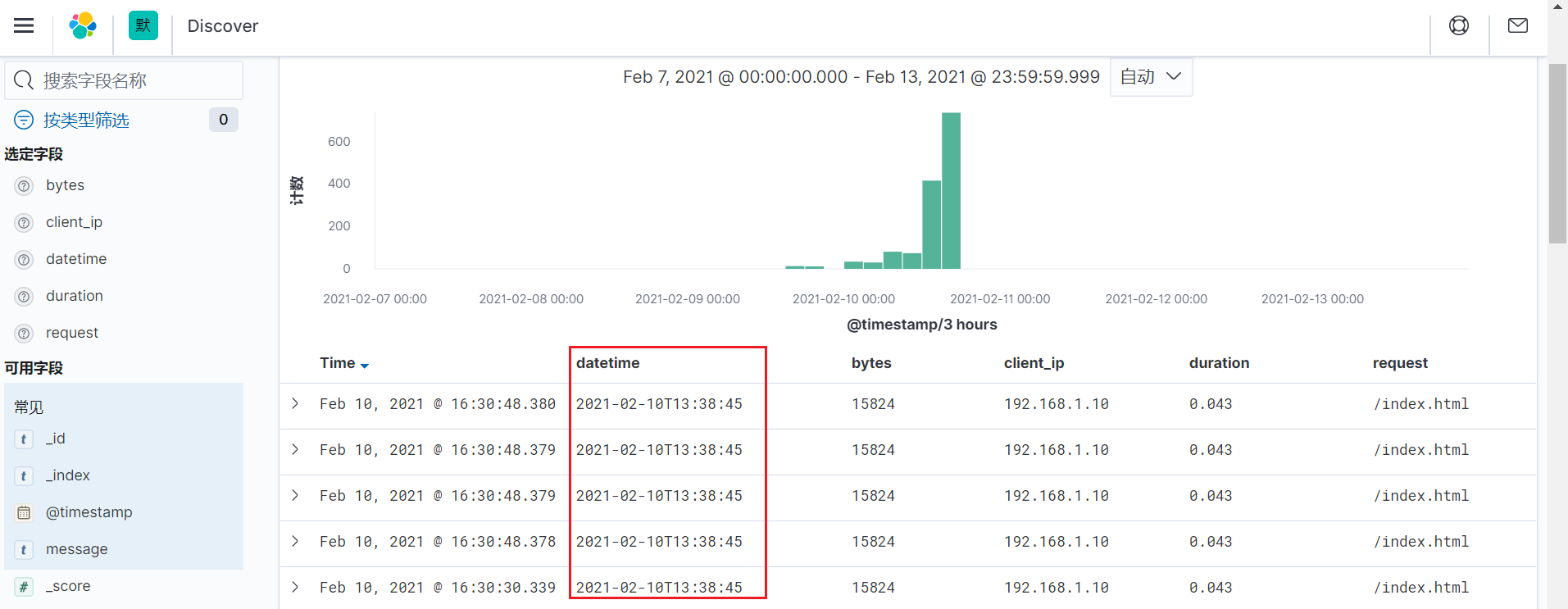
Date插件:用于从指定字段解析日期,一般用于将日志中时间字段 替换Logstash添加的事件时间。 常用字段:
• locale 语言环境
• match 指定匹配时间的字段
• target 将匹配的时间存储指定字段,默认@timestamp
示例:将日志中时间字段替换Logstash事件时间
在kibana页面上验证:
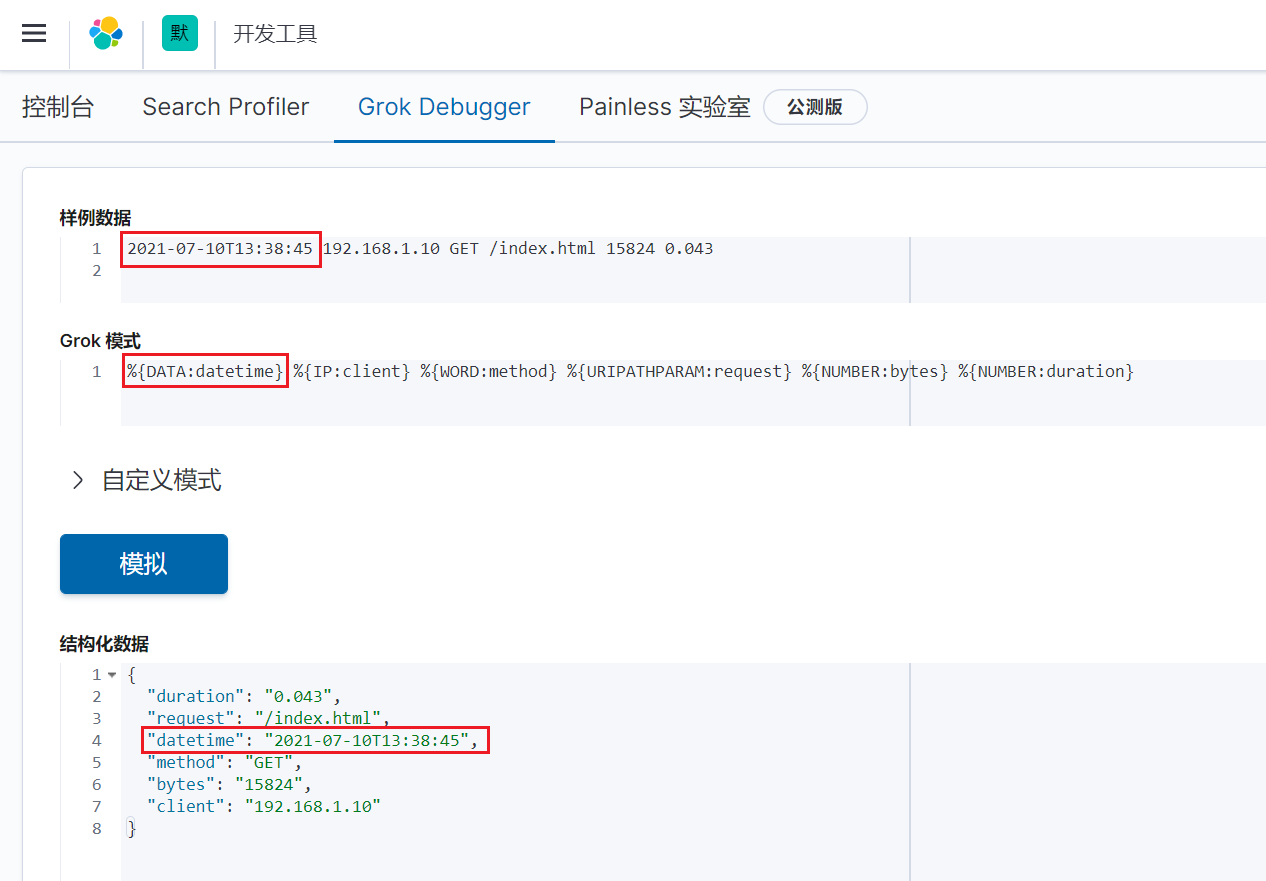
修改logstash配置文件
vim /opt/elk/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test/*.log"
exclude => "1.log"
start_position => "beginning"
tags => "web"
tags => "nginx"
type => "access"
add_field => {
"project" => "microservice"
"app" => "product"
}
}
}
filter {
grok {
match => {
"message" => "%{DATA:datetime} %{IP:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
date {
locale => "en"
match => ["datetime","yyyy-MM-dd'T'HH:mm:ss"]
}
}
output {
elasticsearch {
hosts =>
["192.168.0.11:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
|
热加载配置
在kibana页面上查看